

Customer Killers: Dlaczego operatorzy wyjaśniający zabijają twoją generację potencjalnych klientów?
- Zniszczenie mitów: „Jak zrobić własną kampanię kontekstową?”
- Problem z koncepcją: dlaczego operatorzy wyjaśniający zabierają klientów?
- Cienka czerwona linia: minus słowa lub wyjaśnienie operatorów?
- Jak być w tej sytuacji?
- Krok 1
- Krok 2
- Jak uzyskać wysoki CTR dla nieznanych żądań?
- Jak elastycznie dostosować koszt kliknięcia w oparciu o dane średniego rynku?
- Listy regionalne (miasta) wykluczających słów kluczowych dla Białorusi, Rosji i Kazachstanu:
- 2. Nieruchomości
- 3. Turystyka
- 4. Auto
- 5. SEO i kontekst
- 6. Telefony
- 7.Forex
- 8. Bilety lotnicze
- 9. Laptopy
- 10. Listy regionów
Jeśli jesteś właścicielem firmy lub praktykiem w reklamie kontekstowej, tytuł artykułu prawdopodobnie już złamał ci spokój ducha. Jeśli tak, to prawdopodobnie dużo tęsknisz. Jednak twoi konkurenci najprawdopodobniej nie mają mniej błędów - sukces zależy tutaj od tego, kto reaguje szybciej.
W Direct i ogólnie w reklamie kontekstowej istnieje wiele mitów i urojeń: od najpopularniejszego „Direct się nie opłaca”, aż po szaleństwo na zaawansowanej analizie z miesięcznym budżetem kampanii w wysokości 30 000 rubli. Dzisiaj postaramy się poradzić sobie z jednym z tych mitów, zatytułowanym „Jak zrobić kampanię kontekstową własnymi rękami” (bezpłatnie, bez rejestracji i SMS-ów).
Zniszczenie mitów: „Jak zrobić własną kampanię kontekstową?”
Trudno więc powiedzieć, dlaczego tak się stało, ale przeważająca większość przedsiębiorców i wyspecjalizowanych specjalistów pracuje według następującego schematu:
1) Sparsuj rdzeń semantyczny z Wordstat i oczyść go trochę za pomocą najbardziej prymitywnych narzędzi
2) Utwórz kampanię, w której 1 słowo = 1 reklama
3) Zastosuj do wszystkich wyrażeń operatora „cytaty” w formacie „słowo kluczowe” lub „! Klucz! Słowo”
4) Uruchom kampanię
5) W tym momencie zazwyczaj zwykle pisze się o leadach, połączeniach lub po prostu pisze „Profit!”. Jednak w praktyce taka kampania daje 4-5 razy mniej klientów niż mogłaby, a tak jest również w przypadku, gdy firma jest w stanie odzyskać otrzymany ruch.
Jeśli znajdziesz funkcje znane w powyższym schemacie, czytaj dalej.
Problem z koncepcją: dlaczego operatorzy wyjaśniający zabierają klientów?
Najbardziej problematycznym punktem powyższego wspólnego schematu jest punkt 3 : „Zastosuj operatora„ cytaty ”do wszystkich fraz”
Przejdźmy do liczb. Jak wiecie, z roku na rok rośnie tylko średnia długość żądania, o czym można dowiedzieć się z publicznie dostępnych badań Yandex:
Badanie z 2008 roku , udział 4-słownictwa wynosi 26%, średnia długość to 2,5 słowa w porównaniu do 1,2 słowa w 1997 r. w momencie uruchomienia Yandex:
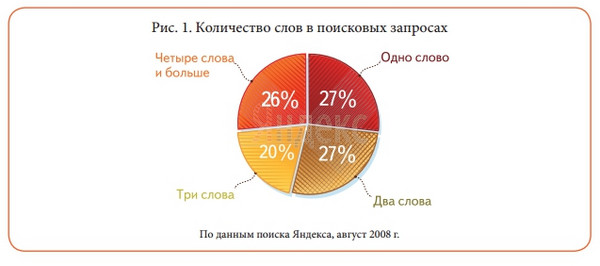
Wyświetl pełny rozmiar
Ankieta z 2009 roku średnia długość to 3 słowa w porównaniu do 2,5 słowa w 2008 roku. Cytat:
„W ciągu roku udział zapytań jednowyrazowych na yandex.ru spadł ponad czterokrotnie, ale udział zapytań o długości czterech lub więcej słów wzrósł o prawie 80%”.
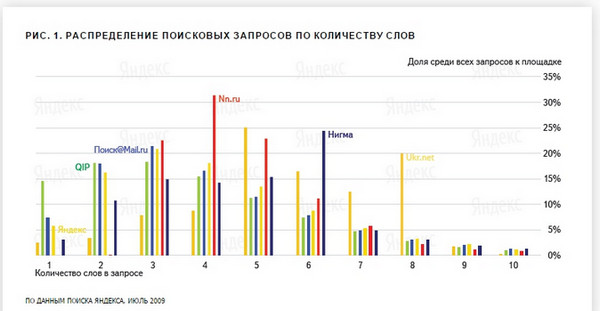
Wyświetl pełny rozmiar
Badanie z 2011 roku Średnia długość to 3,2-3,5 słów w porównaniu do 3 słów w 2009 roku. Cytat:
„Prośby mężczyzn o Yandex są nieco krótsze niż prośby kobiet - średnio odpowiednio 3,2 i 3,5 słowa”.

Wyświetl pełny rozmiar
Ankieta 2014. nie podaje już danych dotyczących długości żądań, ale informuje, że:
„Większość zapytań - średnio około 80% - nie osiąga nawet 10 000 najlepszych (ok. Ed. Według ruchu) i tworzy tzw. Ogon wyszukiwania. W dużych miastach ten ogon jest nieco dłuższy - użytkownicy lokalni mają bardziej zróżnicowane żądania. ”
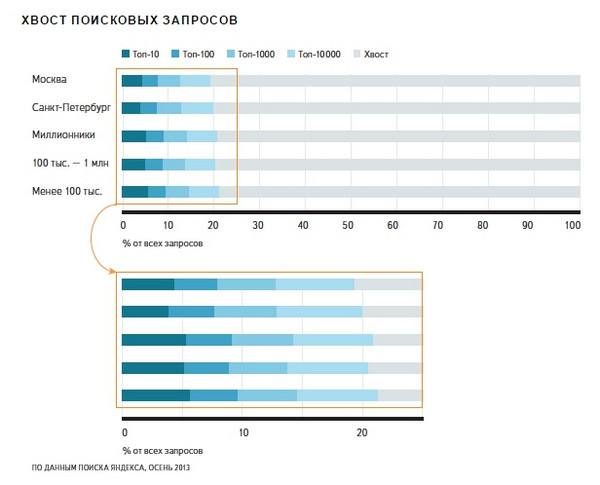
Wyświetl pełny rozmiar
A teraz uwaga - w tym miejscu ma miejsce całe skupienie. Koncentruje się na celowym pominięciu. Yandex uczciwie mówi nam, że podstawą wyszukiwania jest ogon o niskiej częstotliwości. Jednakże tego ogona o niskiej częstotliwości nie można znaleźć w Wordstacie, po prostu go nie ma.
Przykład:
Wordstat - parsowanie „mebli” (maj 2015) bez określenia regionu o głębokości 6, otrzymało 112175 unikalnych żądań, z czego 98980 żąda dokładnej częstotliwości różnej od 0.
Baza MOAB - parsowanie bez określania regionu, daje 3 987 908 zapytań, czyli prawie 4 miliony słów kluczowych o potwierdzonym ruchu niezerowym.
Różnica wynosi 40 razy.
A teraz liczby suche: dostaliśmy klucze z bazy danych MOAB, analizując otwarte liczniki Yandex.Metrica, jednocześnie dając nam pełną historię ponad 100 000 witryn z ~ 30 000 000 witryn połączonych z Metric. Oznacza to, że po porównaniu danych do zaledwie 3% witryn, otrzymaliśmy 40 razy więcej słów kluczowych niż Wordstat. Powstaje pytanie: jaki procent znanych Yandexów tylko z Keyword Metrics daje Yandex Wordstat?
Używając tej próbki jako przykładu, można obliczyć, że tylko około 0, 075%.
Oczywiście szacunek ten jest bardzo trudny, ale pomaga zrozumieć, jak niewiarygodne są publiczne źródła słów kluczowych - używając tylko Wordstat:
a) uzyskać statystycznie zawodną próbkę. Ludzie pytają o wiele bardziej zaawansowane zapytania niż w programie Wordstat. Słowniczki 7 i 8 mogą generować wiele leadów i dziesiątki przejść dziennie, podczas gdy ich dokładna częstotliwość Wordstat będzie równa lub bliska zeru z powodu opóźnienia w otrzymywaniu danych i / lub nieprawidłowego wyświetlania danych
b) uzyskać najbardziej zawyżone i konkurencyjne zapytania dostępne dla wszystkich innych reklamodawców
i wreszcie najważniejsze:
c) w programie Wordstat otrzymujesz te same 20% najczęstszych żądań, które składają się na „najlepsze” tematy. Następnie śmieci są zazwyczaj filtrowane, a żądania są ujęte w cudzysłów, ograniczając obszar wyświetlania, aby uzyskać większy CTR.
Ale problem polega na tym, że żądania zebrane w Wordstacie przenoszą tylko 10-15% całego tematu ruchu. Oznacza to, że używając operatorów, odmawiasz 85% tematycznych tematów ruchu, ograniczając zasięg. Te 85% to zapytania o bardzo niskiej częstotliwości. Jest ich wiele, składają się z dużej liczby słów i są stale łączone. W czasie kompilacji kampanii wiele z nich w ogóle nie może być przypisanych do wyszukiwania - ale w sumie, cała ta ogromna różnorodność rzadkich zapytań utworzy najtańsze oferty w pustej micronishie, o której wszyscy lubią rozmawiać.
W ten sposób wyjaśniliśmy problem. Większość ruchu w wyszukiwarkach generowana jest przez zapytania, których nie ma w Wordstacie, często nie są one nigdzie spotykane, ponieważ często nie są w ogóle ustawiane lub były zadawane 1-2 razy. Jest wiele takich żądań, w sumie tworzą ogromny ruch. Używanie operatorów wyjaśniających, zwłaszcza podczas pracy z najpopularniejszymi zapytaniami z Wordstat, pozwala na walkę tylko o 10-15% rzeczywistych możliwych trafień.
Dlatego musimy odpowiedzieć na kilka pytań:
- jak reklamować dużą liczbę zapytań o niskiej częstotliwości?
- Jak reklamować żądania, które nie są jeszcze ustawione?
- jak uzyskać maksymalne pokrycie niezbędnych żądań, niezawodnie odcinając nadmiar? Jak odciąć wszystkie „niekomercyjne” żądania, gdy nawet nie znamy ich dokładnego sformułowania?
Właśnie to teraz mówimy.
Cienka czerwona linia: minus słowa lub wyjaśnienie operatorów?
Kiedy pracujesz z Yandex.Direct, twoje zadanie z formalnego punktu widzenia jest bardzo proste - przynajmniej dla wyszukiwania. Yandex ma codziennie dzienną liczbę wyświetleń, które może sprzedawać w celu wyszukiwania w ogóle przez cały dzień. Twoja reklama zajmuje część tej kwoty, czyli bierzesz część swoich wyświetleń z reklamy od Yandex. Najlepiej jest wyświetlać reklamę tylko tym, którzy mogą ją kliknąć, aby liczba kliknięć była jak najbliższa liczbie wyświetleń. Jeśli na 100 wykonanych przez Ciebie wyświetleń reklama zostanie kliknięta raz, Yandex obciąży Cię opłatą w wysokości 10 USD za kliknięcie, tj. Przy CTR 1% koszt kliknięcia wyniesie 10 USD. Jeśli na 100 wykonanych wyświetleń reklama zostanie kliknięta 10 razy, Yandex obciąży Cię 1 dolarem za 1 kliknięcie, tzn. Jeśli CTR wzrośnie 10-krotnie do 10%, koszt za kliknięcie spadnie 10-krotnie.
Ważną rzeczą jest to, że Yandex w każdym przypadku otrzyma te same 10 dolarów, które pierwotnie chciał otrzymać, co daje 100 wyświetleń - w rzeczywistości Yandex sprzedaje wyświetlenia, pakując je w formularz „pay per click”.
Jest to oczywiście bardzo trudny schemat, ale wystarczy zrozumieć znaczenie gry: gdy pokażesz swoją reklamę tym, którzy jej nie potrzebują (= tym, którzy jej nie klikają), Yandex jest ubezpieczony od utraty zysku i przegrywasz przepłacanie pieniędzy za drogie kliknięcia. W związku z tym wyjaśnimy zadanie - potrzebujemy minimum wyświetleń i maksymalnej liczby kliknięć, chociaż nie wiemy i nie możemy znać większości żądań, z którymi pracujemy, mamy wyraźny brak informacji.
Jak być w tej sytuacji?
W zasobach: mamy narzędzia do zarządzania liczbą wyświetleń (operatory, wykluczające słowa kluczowe), mamy narzędzia do rozszerzania rdzenia semantycznego (wskazówki do wyszukiwania przez Kluczowy kolektor lub MOAB Zaproponuj , statystyki własnej witryny, statystyki innych witryn MOAB Pro )
Pasywnie: nie znamy dokładnego sformułowania większości próśb
Teraz dochodzimy do najbardziej interesującego - krok po kroku schematu działania. Czas teorii minął, czas ćwiczyć.
Krok 1
Na pierwszym etapie potrzebujemy rdzenia semantycznego, który wyróżnia się maksymalną pewnością statystyczną.
Czym jest pewność statystyczna?
Podczas pracy z dużymi danymi często nie można (tak, nie jest to konieczne) przetwarzania wszystkich dostępnych danych. W tym przypadku bierzesz pewien statystycznie wiarygodny segment danych, analizujesz go, a następnie używasz uzyskanych danych, tak jakbyś analizował całą macierz. Mówiąc prosto, możesz podać przykład ośrodków socjologicznych - „Centrum Lewady” lub „VTsIOM”: podczas przeprowadzania ankiet przeprowadzany jest zwykle wywiad tylko 1600 osoba rozprowadzana równomiernie w całej Rosji i okazuje się, że dystrybucja opinii wśród ogółu ludzi zasadniczo nie różni się od dystrybucji opinii w badanej próbie 1600 osób.
Zrobimy to samo, aw pierwszym etapie postaramy się uzyskać najbardziej wiarygodną próbkę, do której możemy dotrzeć. Szczegółowo opisaliśmy źródła tej próbki. tutaj . Zaznaczam, że do dziś najbardziej kompletnym i niezawodnym źródłem semantyki są statystyki witryn z bogatym ruchem organicznym lub kontekstowym.
Mamy próbkę. Weźmy na przykład próbkę „żądania sufitów napinanych” z bazy MOAB Pro.
Pobieranie próbek z MOAB Pro - 391 045 żądań, dla znajomości, możesz pobrać plik z 2000 najczęstszych żądań
Przykład z MOAB Suggest - 102 166 wniosków, możesz pobrać pełny plik
Krok 2
Tylko na pierwszy rzut oka próbka wydaje się mieszanką chaotycznych zapytań, które nie są ze sobą powiązane. W rzeczywistości najprostsze grupowanie wykonywane przy użyciu Narzędzie analizy grupowej Key Collector wykrywa podział jądra na całkowicie odrębne segmenty.
Zauważ, że należy wykonać grupowanie. „Oddzielnymi słowami” Jest to wskazane w panelu ustawień analizatora.
Podobna analiza, na przykład, jak widać na powyższym obrazku, ujawnia całkowicie jasną grupę żądań informacji „stopionych” - wszystkie żądania zawierają różne grupy tego czasownika. To pokazuje nam, że istnieje segment rzeczywistych interesów użytkowników zgrupowanych wokół problemu topnienia sufitu napinanego.
Pomimo tego, że w gruncie rzeczy znamy tylko niewielką część prawdziwych zapytań tego segmentu, możemy dodać czasownik „stopić” do pliku zatrzymania, który całkowicie zabrania wyświetleń wszelkich odmian tego zapytania, to znaczy „odcina” ruch w całym segment.
Podobną operację segmentu minus można wykonać dla bardziej popularnych segmentów, na przykład:
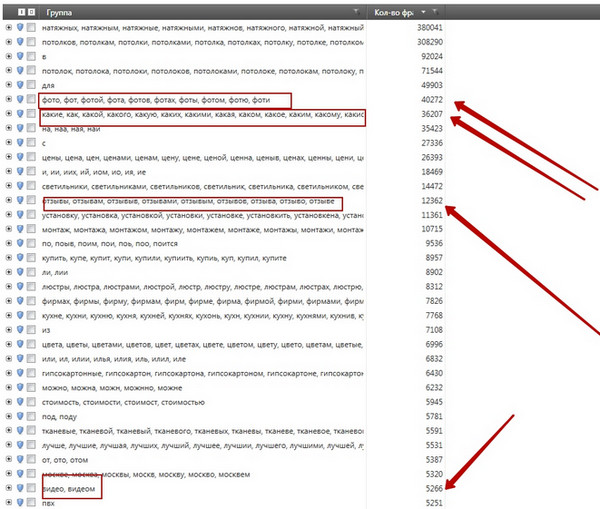
Wyświetl pełny rozmiar
Oczywiste jest, że takie segmenty jak „opinie” lub „wideo” raczej nie zapewnią wysokiej konwersji na kupujących, jest oczywiste, że powinny zostać dodane do zatrzymania słów. Zwróć uwagę na liczby obok segmentów - liczby te oznaczają liczbę żądań w segmencie - na przykład segment „zdjęcie” zawiera prawie 40000 żądań, z grubsza mówiąc, stanowi około 10% ruchu we wszystkich przedmiotach.
Teraz wyobraź sobie - analizując segmentację, spędziliśmy tylko 1-2 minuty, aby zobaczyć pierwszą stronę wyników. W tym czasie dodaliśmy cztery segmenty do pliku zatrzymania:
- recenzje
- które
- zdjęcie
- wideo
Łącznie te 4 segmenty zawierają około 94 000 żądań, co stanowi przybliżoną wartość jednej czwartej ruchu w temacie. Oznacza to, że pytanie nie jest nawet ilościowe, ale jako minus słów - możesz wymyślić lub pożyczyć od swojego przyjaciela tyle słów minus, ile chcesz, ale co oni mają wspólnego z prawdziwym rdzeniem semantycznym?
Spróbujmy rozwinąć ten pomysł dalej: w końcu, jeśli spojrzymy na 20% najlepszych linii w klastrowaniu i oznaczymy słowa kończące jako „niepotrzebne” segmenty biznesowe, „odetniemy” o 90-95% „niepotrzebny” ruch.
Jeśli cofniemy się nieco, zobaczymy, dlaczego potrzebujemy statystycznie wiarygodnej tablicy - segmenty statystycznie wiarygodnej tablicy o bardzo dużej dokładności kopiują rzeczywistą tablicę z wieloma nieznanymi żądaniami.
Jednocześnie, pomimo tego, że wnioski mogą być formułowane zgodnie z twoimi oczekiwaniami, same segmenty nadal pozostaną takie same - a gdy zostanie przeprowadzone grupowanie i jego późniejsza analiza, nadal będziemy „łapać” i „odcinać” większość segmentów, które nie są skuteczne w biznesie.
Zatem możemy sformułować kilka ogólnych zasad:
- dla minusów potrzebujemy najbardziej statystycznie wiarygodnego pliku, maksymalnych żądań z potwierdzonym ruchem - sztuczna semantyka jest tutaj nieskuteczna
- minus powinien być wykonywany na podstawie grupowania, natomiast jeśli potrzebujesz naprawdę dokładnego i efektywnego kontekstu, powinieneś zobaczyć przynajmniej 20% najlepszych linii w klastrze i zidentyfikować nieefektywne segmenty, tworząc z nich plik stop. Ten plik zatrzymania będzie wystarczająco duży, ale da ci w następnym kroku możliwość zrezygnowania z korzystania z wyjaśniania operatorów - ponieważ nawet jeśli nie znasz wszystkich żądań, możesz być pewien, że plik zatrzymania stanie się niezawodną tarczą, która ochroni Cię przed niepotrzebne „trafienia”.
Innymi słowy, mamy dwa narzędzia do regulacji zasięgu - plik zatrzymania i wyjaśnienie operatorów. Posiadając statystycznie wiarygodną tablicę, maksymalnie wykorzystujemy negatywne słowa kluczowe, przenosząc nacisk na nie w „czyszczeniu” ruchu ze śmieci.
Jednocześnie używamy wyjaśniania operatorów o minimum, co z kolei daje nam maksymalne pokrycie tylko dla nieznanych żądań, które w rzeczywistości są rozszerzeniami tych wniosków, które zebraliśmy.
W tym przypadku należy przypomnieć, że Direct rozumie formy słów „stopić” i „stopione” - to znaczy, nie ma znaczenia, jaką formę słowa dodasz do pliku stopu, jednak „stopione” należy dodać osobno - części mowy nie wiążą Directa . Wszystkie znaki specjalne, z wyjątkiem punktu, są równoważne spacji dla Directa, to znaczy numeryczne słowo ujemne (na przykład artykuł) „49-53” zostanie rozpoznane jako dwa oddzielne słowa minus oddzielone spacją, podczas gdy „49,53” zostanie rozpoznane jako pojedyncze słowo stop.
Ważne jest również, aby wspomnieć o punkcie czysto technicznym: najwygodniejszym sposobem na usunięcie śmieci z szeregu fraz kluczowych w celu przejścia do następnego etapu grupowania są wyrażenia regularne zaimplementowane w Key Collector, o których wielu niezaprzeczalnie zapomina lub po prostu nie wie.
Więc wyobraź sobie, że masz plik stop w formacie Yandex.Direct, który zebrałeś analizując klastry w słowniku częstotliwości:
- recenzje, - wideo, -free, -shoot, .... Kijów, -Astana, Władywostok
Możesz przekształcić te frazy w konstrukcje widoku:
recenzja | wideo | darmowe | pobierz | …… | Kijów | Astana | Władywostok
Następnie dodaj wynikową konstrukcję do Key Collector karta z nieczystą tablicą .
W rezultacie w wynikowej próbce znajdą się wszystkie frazy, które pasują do jednego z warunków, to znaczy zawierają „recenzję” lub „wideo” lub „wolny” i tak dalej. Uważaj, by były z niejednoznacznymi słowami, takimi jak „nogi” - stan formatu „nóg” zajmie pod filtrem „Noginsk”, „Noggano” i „trójnóg”, podczas gdy „Noginsk” i „Noggano” mogą być słowami zatrzymania w określonym kontekst, ale „statywy” nie są.
Zaletą jest to, że z jednej strony można szybko usunąć wszystkie niepotrzebne frazy z tablicy, z drugiej strony można zastosować wynikowe wyrażenie regularne do tablic podobnych obiektów w przyszłości, oszczędzając czas na sprzątanie niepotrzebnych zapytań.
Jak uzyskać wysoki CTR dla nieznanych żądań?
Teraz wyobraź sobie, że wybraliśmy ogromny plik zatrzymania, korzyść jest teraz dopuszczalny rozmiar pliku zatrzymania w Yandex.Direct - 20 000 znaków. W ten sposób „odcinamy” cały ruch o potencjalnie niskiej konwersji - wszystkie segmenty, których znaczniki są pewnymi charakterystycznymi słowami, są dodawane do naszego pliku zatrzymania.
Jednak wykonaliśmy tylko połowę pracy. Nadal stoimy przed pytaniem - jak osiągnąć efektywne wrażenia nie tylko i nie tyle w przypadku zapytań, które są zawarte w naszym rdzeniu semantycznym, ale także dla ich rekombinacji i rozszerzeń.
Najbardziej skutecznym sposobem jest dalsza praca z segmentacją. Spróbuj odwrócić uwagę od nieefektywnego podejścia „1 klucz = 1 ogłoszenie”. Wyobraź sobie, że jedna reklama to jeden segment z analizy grupowej z dołączonymi do niej żądaniami. Spróbujmy sobie wyobrazić zalety i wady tego podejścia.
Weźmy na przykład Segment „odbudowy” . Uważny czytelnik może oczywiście zauważyć, że w segmencie pojawiły się prośby, które można formalnie uznać za „śmieci” - ale nie zrobiliśmy poważnego czyszczenia tej tablicy - po prostu pokazaliśmy małym przykładem, jak to się robi w praktyce. Dlatego warunkowo wyobrażamy sobie, że wszystkie żądania w segmentach są ukierunkowane.
Tak więc w segmencie „Przywracanie” są 24 kluczowe zapytania:
przywrócenie sufitu z tkaniny
odbudowa wanien sufitowych
odnawianie sufitów napinanych
naprawa sufitów napinanych odnawianie cięć
przywrócenie sufitów napinanych
przywrócenie nacięć sufitów napinanych
czy odnawianie sufitów podwieszanych
balkony, balkony, odnawianie wanien sufitowych
naprawa i odbudowa sufitu napinanego
naprawa i odnawianie sufitów napinanych
naprawa sufitów napinanych odnawianie cięć w Jekaterynburgu
naprawa sufitów napinanych odnowienie cięć w Ufa
naprawa sufitów napinanych odnawianie cięć na własną rękę
naprawa sufitów napinanych, przywracanie cięć
przywrócenie rozciągliwych otworów sufitowych
przywrócenie sufitów napinanych Petrozavodsk
przywrócenie sufitu napinanego po zalaniu
przywrócenie sufitów napinanych po zalaniu, firmy telefoniczne
odbudowa sufitu zrób to sam
samodzielne odnowienie sufitu napinanego
przywrócenie sufitów napinanych pcv
renowacja telefonów sufitów napinanych
odbudowa ciętego sufitu stretch
firmy do drobnych napraw i renowacji sufitów napinanych
Wartość segmentów nie jest określona konkretnymi frazami, ale tym, że dają nam wiedzę na ten temat - istnieje taka grupa zainteresowań użytkowników. Możemy więc utworzyć odpowiednią grupę reklam:
Tytuł: Odnowa sufitu napinanego
Tekst: Naprawa sufitów pod klucz! Wymeldowanie i ocena jest bezpłatna.
Następnie przesyłamy reklamę do Direct wraz z powyższymi kluczami i uruchamiamy wrażenia. Klucze oczywiście rozładowują się bez operatorów.
Co otrzymujemy w rezultacie?
Po pierwsze, zwróć uwagę na tzw. „Podstawa” segmentu. Wszystkie słowa kluczowe segmentu obejmują 3 słowa - przywrócenie, sufity napinane. Oznacza to, że reklama wygeneruje wyświetlenia tylko dla tych żądań, które zawierają wszystkie 3 słowa w tym samym czasie + wszelkie dodatki i rozszerzenia, o których nie wiemy.
Oznacza to, że jest prawdopodobne, że wiele kluczy segmentu zasadniczo nie wygeneruje wrażeń. Większość wyświetleń pojawi się na życzenie „przywrócenie sufitów napinanych”, ponieważ przyciągnie rozszerzone wyświetlacze na klawiszach formatu „przywrócenie sufitów napinanych + rozszerzenie”.
Jednocześnie nie będziemy przyciągać wyświetleń nieznanych rozszerzeń, których nie potrzebujemy, ze względu na obecność pliku zatrzymania jakości. A co z klikalnością „nieznanych” żądań, których potrzebujemy?
Spójrz na problem :

Reklamuj się na dowolnych słowach kluczowych segmentu, w tym nieznanym rozszerzeniu, otrzymasz po prostu niesamowity CTR: najważniejszy dla słowa użytkownika „przywrócenie” nie znajduje się w żadnej z reklam Yandex.Direct, a to w tytule reklamy przyciągnie największą uwagę i na każdej pozycji specjalnego umieszczenia.
Ponadto będziesz pobierać ruch z dostawy ekologicznej:

W pozycjach emisji organicznej i Direct w najbardziej konkurencyjnym regionie kraju nie ma ani jednego słowa „przywrócenie” - w Moskwie, aw Directach w nagłówkach nie ma nawet synonimu „naprawy”! Byłoby niedopuszczalnym prezentem dla konkurentów, aby nie wykorzystać tej sytuacji - niemniej jednak jest to standardowa sytuacja dla większości wyjść o niskiej częstotliwości.
Nie ma wątpliwości, że w takich warunkach będzie można uzyskać maksymalny ruch nawet z pierwszej, ale z dowolnej, najtańszej pozycji specjalnej lokacji. Później omówimy dokładnie, jak korzystać i zmienić tę sytuację na naszą korzyść.
Po drugie, zwróć uwagę na sposób tworzenia tytułu i tekstu. Nagłówek kopiuje podstawę grupy - trzy słowa zawarte we wszystkich klawiszach segmentu mają 29 znaków. Następnie przychodzi pierwsze zdanie tekstu, składające się z 24 znaków. 24 + 29 = 53, czyli pasujemy do reguły „ 56 znaków „Po ekstradycji w praktyce otrzymujemy ogłoszenie:
Tytuł: Renowacja sufitów napinanych - naprawa sufitów pod klucz!
Tekst: Sprawdź i sprawdź za darmo.
W rezultacie, podczas żądania dowolnego, nawet jeśli rekombinowane zapytanie w tym segmencie, otrzymamy co najmniej 4 wyróżnione słowa w tym nagłówku:
- przywrócenie - 1 wpis
- napięcie - 1 wpis
- sufity - 2 wpisy
Należy pamiętać, że nie było przypadkiem, że „naprawa” dostała się również do rozszerzonego tytułu - zbyt często - aż 8 razy w słowach kluczowych segmentu, na wynikach tego zapytania „naprawa” jest wyróżniona fragmentem i jest uznawana za synonim. Jest to ważny sygnał - oznacza to, że prawdopodobieństwo jego użycia jest wysokie wraz z podstawą grupy, co oznacza, że w tym przypadku konieczne jest uzyskanie użycia w nagłówku w celu zwiększenia współczynnika klikalności dla takich zapytań.
Niektóre z zapytań w tej grupie generują wrażenia, inne nie.
W każdym razie całkowita jakość i ilość docelowego ruchu z kampanii zebranej w ramach takiej architektury przekroczy każde z Twoich oczekiwań w porównaniu z kampaniami zebranymi w standardowej architekturze „1 klucz = 1 reklama”. Zgodnie z doświadczeniem klientów MOAB, którym doradzaliśmy, średni koszt ołowiu po takim ponownym montażu kampanii spadł 3-4 razy.
Jest jednak bardzo ważny punkt: pracując z losowym zestawem żądań, musimy stale monitorować podstawę każdej reklamy. W tym przypadku podstawą jest żądanie klucza, które składa się tylko z tych słów, które są zawarte w każdej (!) Reklamie słów kluczowych.
W tym przypadku podstawą jest - [przywrócenie sufitów podwieszanych]
Tak się złożyło, że ten klucz naturalnie wpadł do grupy „przywracania”. To z kolei doprowadzi do tego, że jeśli prośba użytkownika jest nam nieznana - [przywrócenie sufitów napinanych Moskwa Lenin Avenue] - nasze ogłoszenie zostanie pokazane na ten wniosek, ponieważ klucz ten stanowi rozszerzenie [przywrócenia sufitów napinanych].
Spójrzmy jednak na inny segment - [sufity z korka]
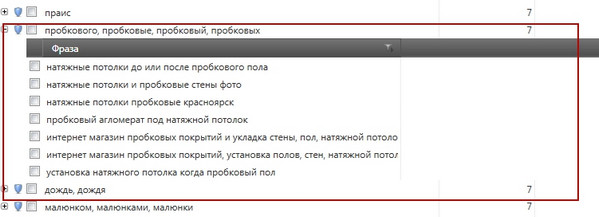
Oglądaj w pełnym rozmiarze
Faktem jest, że kiedy pracujemy z jądrem, w większości przypadków podstawa segmentu naturalnie pojawia się wśród kluczy segmentu i generuje wyświetlenia zgodnie z zaawansowanymi wariantami zapytania. Jeśli jednak spojrzysz na zrzut ekranu, zobaczysz, że w tym segmencie brakuje podstawy [sufity napinane z korka], tzn. Wyświetlacz nieznanego żądania - [sufity napinane w korku Moskwa] - nie wystąpi.
W takim przypadku sytuacja ta powinna być monitorowana niezależnie i sztucznie, formalnie rzecz biorąc, klucz [sufity korka] powinien zostać dodany do grupy w celu uzyskania wyświetleń dla wszystkich nieznanych żądań tego segmentu.
Przy okazji, każdy, kto chce naprawdę poważnie pracować z zarządzaniem reklamą kontekstową opartą na operatorach, polecam zapoznać się z naszym artykułem „ Sześć tajemnic reklamy kontekstowej „W szczególności - w paragrafie 3, który mówi, jakie dodatkowe środki można podjąć, aby obniżyć koszt wyświetleń na stosunkowo drogich żądaniach z Wordstat, aby jednocześnie zaoszczędzić wyświetlenia na„ nieznanych ”zapytaniach.
Jak elastycznie dostosować koszt kliknięcia w oparciu o dane średniego rynku?
Ostatnim etapem tworzenia kampanii jest kompetentna regulacja stawek. Przyjrzyjmy się standardowemu podejściu „1 klucz = 1 reklama” pod względem stawek. Okazuje się, że wszyscy reklamodawcy współpracują z Wordstatem, biorąc stamtąd ten sam zestaw „komercyjnych” fraz. Następnie frazy z operatorem „cytaty” są ładowane na konto i kampania jest uwzględniana. W rezultacie mamy ogromną grupę reklamodawców, którzy konkurują ze sobą o ściśle ograniczony zestaw zwrotów. Oczywiście rozgrzewa to aukcję specjalnie dla tych fraz, podczas gdy konkurencja o „nieznane” wnioski pozostaje stosunkowo „spokojna”.
Zostawmy jednak teorię - dziś mamy dla Was kilka ważnych wskazówek praktycznych.
1. Pracuj z ceną rynkową słów kluczowych.
Jak ją rozpoznać?
Bardzo proste: dodaj wyczyszczoną tablicę fraz do Key Collector, a następnie odznacz koszt za kliknięcie dla każdej frazy .
W wyświetlonym oknie wybierz następujące ustawienia:
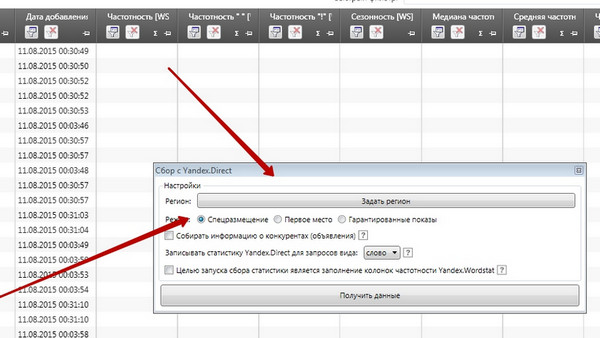
Oglądaj w pełnym rozmiarze
W polu „Ustaw region” musisz określić region kierowania geograficznego, z którym pracujesz. Następnie poczekaj chwilę, a następnie odwołaj się do informacji otrzymanych w polu CPC YD:

Oglądaj w pełnym rozmiarze
Oblicz średni koszt za kliknięcie przez wynikową tablicę. Następnie wybierz „Średnia” i uzyskaj wynik:
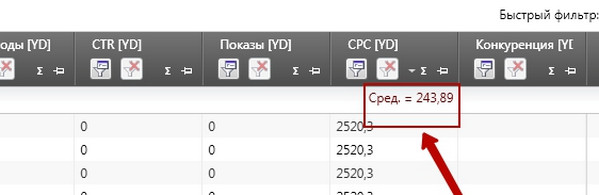
Oglądaj w pełnym rozmiarze
Wynik ten wynosi prawie 250 rubli - średni koszt rynkowy kliknięcia na podstawie „Prognozy budżetowej” Direct. Aby obliczyć wartości prognozy Direct, naturalnie przyjmuje średnią wartość systemu, w praktyce średni koszt za kliknięcie będzie znacznie niższy.
Jednak uzyskując tę średnią wartość i pracując z dużą liczbą fraz, możemy przynajmniej w przybliżeniu z góry zrozumieć, które frazy są celowo zawyżone, a które niedoceniane.
Jest to wartość średniej wartości rynkowej (lub jej pochodnych, na przykład średnia cena * 0,50), którą zalecamy stosować w pierwszym etapie wydzielenia kampanii jako maksymalną stawkę ustaloną u oferenta. Następnie stawka ta może zostać dostosowana, biorąc pod uwagę rzeczywistą sytuację marż i reklam kontekstowych zwrotu.
Jak pracować z oferentami?
Współpracujemy z oferentem DirectManager i polecam go naszym partnerom. Wśród zalet tego oferenta jest przede wszystkim ogromny zestaw zmiennych, z których można pisać własne strategie i częste aktualizacje (do 1 raz na 5 minut).
W przypadku kampanii utworzonych zgodnie z architekturą opisaną powyżej używamy następującej kombinacji strategii:
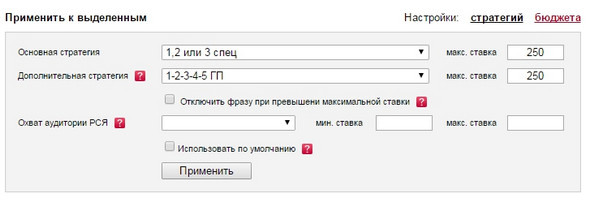
Oto widok tekstowy głównej strategii:
jeśli (1C jest mniejsze niż 2C, a 1C jest mniejsze niż 3C) {
1C + 0,02
} inaczej, jeśli (2C jest mniejsze niż 1C, a 2C jest mniejsze niż 3C) {
2С + 0,02
} inaczej {
3С + 0,02
}
Oto widok tekstowy dodatkowej strategii:
jeśli (1M to mniej niż 2M, a 1M to mniej niż 3M, a 1M to mniej niż 4M, a 1M to mniej niż 5M, a 1M to mniej niż HH) {
1M + 0,02
}
w przeciwnym razie, jeśli (2M jest mniejsze niż 1M, a 2M jest mniejsze niż 3M, a 2M jest mniejsze niż 4M, a 2M jest mniejsze niż 5M, a 2M jest mniejsze niż HM) {
2M + 0,02
}
w przeciwnym razie, jeśli (3M mniej niż 1M i 3M mniej niż 2M i 3M mniej niż 4M i 3M mniej niż 5M i 3M mniej niż HM) {
3M + 0,02
}
w przeciwnym razie, jeśli (4M jest mniejsze niż 1M, a 4M jest mniejsze niż 2M, a 4M jest mniejsze niż 3M, a 4M jest mniejsze niż 5M, a 4M jest mniejsze niż HM) {
4M + 0,02
}
w przeciwnym razie, jeśli (5M mniej niż 1M i 5M mniej niż 2M i 5M mniej niż 3M i 5M mniej niż 4M i 5M mniej niż HH) {
5M + 0,02
}
w przeciwnym razie {SE + 0.02}
Co oznaczają te wszystkie liczby w praktyce?
Co 5 minut licytant uzyskuje dostęp do interfejsu API Yandex.Direct i otrzymuje ceny za wszystkie specjalne miejsca docelowe dla określonej frazy. Spośród trzech wartości uzyskanych dla naszej konkretnej kampanii, reklamy i słowa kluczowego oferent wybiera najtańszą pozycję - nie ma znaczenia, czy trzecia jest drugą czy pierwszą. Następnie porównuje koszt tej najtańszej pozycji z maksymalną stawką.
Jeśli maksymalna oferta jest niższa niż koszt najtańszej specjalnej pozycji, wówczas kalkulacja jest powtarzana już dla gwarancji - oferent wybiera najtańszą pozycję w gwarancji. Jeśli koszt najtańszej pozycji mieści się w maksymalnym limicie oferty (który jest równy średniemu kosztowi rynkowemu kliknięcia w tablicę), oferent zaczyna walczyć o pozycję, dodając 0,02 do kosztu najtańszej pozycji, po czym reklama pojawia się na pozycji, której potrzebujemy.
Podsumowując, chciałbym, w miarę możliwości, ułatwić tworzenie kampanii reklamowych naszym czytelnikom, udostępniając im gotowe listy minus słowa dostępne do pobrania (będą one dostępne po opublikowaniu artykułu na stronie 19 sierpnia 2015 r. - przyp. Red.).
Podane słowa minus są zbierane na podstawie analizy odpowiednich próbek z bazy danych MOAB. Wymieniono 200 najczęściej występujących słów minusowych. Wszystkie słowa minus są podawane w 3 formatach: w formacie wyrażenia regularnego dla Key Colletor, w formacie, który można natychmiast wstawić do pliku zatrzymania w interfejsie kampanii Yandex.Direct, a także w formacie, który jest używany do importowania słów zatrzymania do projektu w programie „ Mega lemma „
Listy regionalne (miasta) wykluczających słów kluczowych dla Białorusi, Rosji i Kazachstanu:
1. Banki
- kredyt - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- pożyczka - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
- wkład - format bezpośredni , format wyrażeń regularnych , Format Megalamem
2. Nieruchomości
- wynajem mieszkania - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
- nieruchomości - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- hipoteka - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
3. Turystyka
- wycieczki - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- kupony - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
4. Auto
- auto - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
5. SEO i kontekst
- seo - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- reklama kontekstowa - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
- bezpośredni Format bezpośredni , format wyrażeń regularnych , Format Megalamem
- promocja strony internetowej - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
6. Telefony
- Samsung - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- jabłko - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
7.Forex
- forex - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
8. Bilety lotnicze
- kup bilety - format bezpośredni , format wyrażeń regularnych , Format Megalamem
9. Laptopy
- laptop - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
10. Listy regionów
- Rosja - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- Białoruś - format bezpośredni , format wyrażeń regularnych , Format Megalamem
- Kazachstan - Format bezpośredni , format wyrażeń regularnych , Format Megalamem
Zniszczenie mitów: „Jak zrobić własną kampanię kontekstową?Cienka czerwona linia: minus słowa lub wyjaśnienie operatorów?
Jak być w tej sytuacji?
Jak elastycznie dostosować koszt kliknięcia w oparciu o dane średniego rynku?
Zniszczenie mitów: „Jak zrobić własną kampanię kontekstową?
Problem z koncepcją: dlaczego operatorzy wyjaśniający zabierają klientów?
Powstaje pytanie: jaki procent znanych Yandexów tylko z Keyword Metrics daje Yandex Wordstat?
Jak reklamować żądania, które nie są jeszcze ustawione?
Jak uzyskać maksymalne pokrycie niezbędnych żądań, niezawodnie odcinając nadmiar?
Jak odciąć wszystkie „niekomercyjne” żądania, gdy nawet nie znamy ich dokładnego sformułowania?