

Вбивці клієнтів: чому уточнюючі оператори вбивають вашу лідогенераціі?
- Руйнування міфів: «Як зробити контекстну кампанію своїми руками?»
- Проблема концепції: чому уточнюючі оператори забирають у вас клієнтів?
- Тонка червона лінія: мінус слова або уточнюючі оператори?
- Як же бути в такій ситуації?
- Крок 1
- крок 2
- Як домогтися високого CTR з невідомих запитам?
- Як гнучко регулювати вартість кліка на основі середньоринкових даних?
- Регіональні списки (міста) мінус-слів для Білорусії, Росії та Казахстану:
- 2.Недвіжімость
- 3. Туризм
- 4. Авто
- 5. SEO і контекст
- 6. Телефони
- 7.Forex
- 8. Авіаквитки
- 9. Ноутбуки
- 10. Списки регіонів
Якщо ви - власник бізнесу або практикуючий фахівець з контекстної реклами, то заголовок статті, ймовірно, вже порушив ваш душевний спокій. Якщо так - то ви, ймовірно, багато втрачаєте. Втім, у ваших конкурентів, швидше за все, помилок не менше - успіх тут залежить більше від того, хто швидше зреагує.
В Ю Я, та й в контекстній рекламі в цілому, існує безліч міфів і помилок: від самого популярного «Директ не окупається», до божевілля на просунутій аналітиці при місячному бюджеті кампанії в 30000 рублів. Сьогодні ми спробуємо розібратися з одним з цих міфів, під назвою «Як зробити контекстну кампанію своїми руками» (безкоштовно, без реєстрації та СМС).
Руйнування міфів: «Як зробити контекстну кампанію своїми руками?»
Отже, важко сказати чому так сталося, але переважна більшість підприємців і профільних фахівців працюють за такою схемою:
1) Спарс семантичне ядро з Wordstat і трохи почистимо його за допомогою найпримітивніших інструментів
2) Створимо кампанію, в якій 1 слово = 1 оголошення
3) Застосуємо до всіх фразам оператор «лапки» у форматі «ключове слово» або «! Ключове! Слово»
4) Запустимо кампанію
5) В цьому пункті зазвичай прийнято писати що-небудь про ліди, дзвінки або просто писати «Профіт!». Однак на практиці, така кампанія дає в 4-5 разів менше клієнтів, ніж могла б, і це ще в тому випадку, якщо бізнес виявляється в стані окупити одержуваний трафік.
Якщо в схемі, яка наведена вище, ви знайшли знайомі вам риси - читайте далі.
Проблема концепції: чому уточнюючі оператори забирають у вас клієнтів?
Найбільш проблемний пункт наведеної вище поширеною схеми - це пункт 3: "Застосуємо до всіх фразам оператор« лапки »»
Давайте звернемося до цифр. Як відомо, рік від року середня довжина запиту тільки зростає, про це можна дізнатися з публічно доступних досліджень Яндекса:
Дослідження 2008 року , Частка 4-словников 26%, середня довжина 2,5 слова проти 1,2 слова в 1997 році на момент запуску Яндекса:
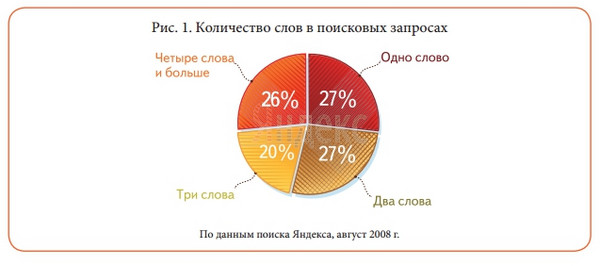
Дивитися в повному розмірі
Дослідження 2009 року , Середня довжина 3 слова проти 2,5 слова в 2008 році. Цитата:
«За рік частка однослівних запитів на yandex.ru впала більш ніж в чотири рази, зате частка запитів довжиною в чотири і більше слів стала більше майже на 80%».
Дивитися в повному розмірі
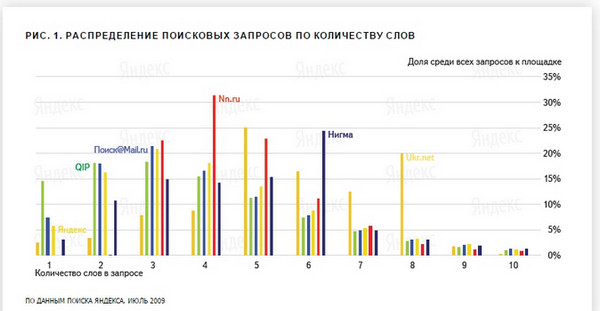
Дослідження 2011 року , Середня довжина 3,2-3,5 слова проти 3 слів в 2009 році. Цитата:
«Чоловічі запити до Яндексу трохи коротше жіночих - в середньому 3,2 і 3,5 слова відповідно».

Дивитися в повному розмірі
Дослідження 2014 року вже не дає цифр по довжині запитів, проте повідомляє, що:
«Велика частина запитів - в середньому близько 80% - не влучає навіть в топ-10000 (прим. Авт. - по трафіку) і становить так званий хвіст пошукових запитів. У великих містах цей хвіст трохи довше - у місцевих користувачів запити різноманітніше ».
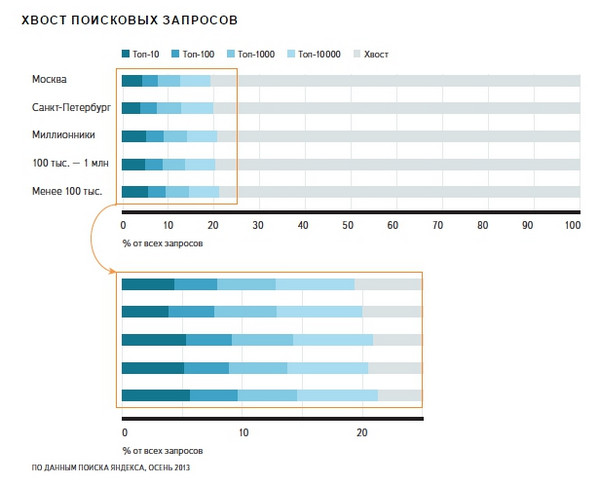
Дивитися в повному розмірі
А тепер, увага - саме в цьому місці і відбувається весь фокус. Фокус - в навмисному замовчуванні. Яндекс чесно говорить нам, що основа пошуку - це низькочастотний хвіст. Однак цей низькочастотний хвіст неможливо знайти в Wordstat, його там просто немає.
приклад:
Wordstat - парсинг за запитом «меблі» (травень 2015) без вказівки регіону, з глибиною 6, отримано 112 175 унікальних запитів, з яких у 98980 запитів точна частотність відрізняється від 0.
База MOAB - парсинг без вказівки регіону, дає 3 987 908 запитів, тобто - майже 4 мільйони ключових слів з підтвердженим трафіком, відмінним від нуля.
Різниця - в 40 разів.
А тепер сухі цифри: ми отримали ключі з бази MOAB шляхом парсинга відкритих лічильників Яндекс.Метрики, Спарс при цьому повну історію по 100 000 сайтів з ~ 30 000 000 сайтів, підключених до Метриці. Тобто, Спарс дані тільки по 3% сайтів, ми отримали в 40 разів більше ключових слів, ніж є в Wordstat. Виникає питання: який відсоток від відомих Яндексу тільки з Метрик ключових слів Яндекс віддає в Wordstat?
На прикладі даної вибірки, можна підрахувати, що всього лише близько 0, 075%.
Звичайно, дана оцінка дуже груба, проте вона допомагає зрозуміти наскільки недостовірні публічні джерела ключових слів - користуючись тільки Wordstat, ви:
а) отримуєте статистично недостовірну вибірку. Люди задають набагато більше розширених запитів, ніж можна побачити в Wordstat. 7 і 8-словники можуть генерувати безліч лидов і десятки переходів в день, при цьому їх точна частотність Wordstat буде рівною або близькою до нуля за рахунок затримки в отриманні даних та / або некоректному їх відображенні
б) отримуєте найбільш переоцінені і конкурентні запити, доступні всім іншим рекламодавцям
і, нарешті, найважливіше:
в) в Wordstat ви отримуєте ті самі 20% найбільш частотних запитів, які формують «топ» тематики. Потім зазвичай фільтрується сміття і запити полягають в «лапки», обмежуючи область показів, щоб домогтися більшого CTR.
Але проблема в тому, що зібрані вами в Wordstat запити несуть тільки 10-15% від загального трафіку тематики. Тобто, використовуючи оператори, ви своїми руками відмовляєтеся від 85% тематичного трафіку тематики, обмежуючи ваш охоплення. Ці 85% - це ультранизькочастотних запити. Їх дуже багато, вони складаються з великої кількості слів і постійно перекомбініруются. На момент складання вашої кампанії, багато хто з них можуть бути взагалі ще не задані до пошуку - але сумарно все це величезна різноманітність рідкісних запитів сформує ті найдешевші ліди в порожніх мікроніші, про які всі так люблять говорити.
Таким чином, ми роз'яснили проблему. Велика частина трафіку в пошукових системах формується запитами, яких немає в Wordstat, найчастіше їх немає взагалі ніде, оскільки вони часто ще взагалі не задані, або ж були задані 1-2 рази. Таких запитів дуже багато, сумарно вони формують гігантський трафік. Використання уточнюючих операторів, особливо при роботі з найбільш розхожими запитами з Wordstat, дозволяє вам боротися лише за 10-15% від реально можливих показів.
Таким чином, ми повинні відповісти на кілька запитань:
- як рекламуватися за великим обсягом НЧ-запитів?
- як рекламуватися за запитами, які ще не задані?
- як отримувати максимум охоплення по потрібних запитах, надійно відсікаючи зайве? Як відсікти все «некомерційні» запити, коли ми навіть не знаємо їх точного формулювання?
Саме про це ми зараз і поговоримо.
Тонка червона лінія: мінус слова або уточнюючі оператори?
Коли ви працюєте з Директом, ваше завдання, з формальної точки зору, дуже проста - по крайней мере, для пошукового розміщення. У Яндекса щодня є якась сума показів, яку він може продати для пошукового розміщення взагалі в цілому за добу. Ваше оголошення займає певну частину від цієї суми, тобто ви забираєте на ваше оголошення у Яндекса частина показів. В ідеалі, ви повинні показувати оголошення тільки тим, хто здатний клікнути по ньому, так, щоб кількість кліків було якомога ближче до кількості показів. Якщо з 100 показів, які ви забрали, по вашій об'яві клацнуть 1 раз, Яндекс візьме з вас 10 доларів за 1 клік, тобто при CTR 1% ціна за клік для вас складе 10 доларів. Якщо з 100 показів, які ви забрали, по вашій об'яві клацнуть 10 разів, Яндекс візьме з вас 1 долар за 1 клік, тобто при зростанні CTR в 10 разів до 10% ціна за клік для вас знизиться в 10 разів.
Важливо тут те, що Яндекс в будь-якому випадку отримає ті ж самі 10 доларів, які він спочатку хотів отримати, віддаючи вам 100 показів - тобто, насправді Яндекс продає покази, упакувавши це в форму «плати за клік».
Це, звичайно ж, дуже груба схема, проте її досить, щоб зрозуміти сенс гри: коли ви показуєте ваше оголошення тим, кому вона не потрібна (= тим, хто по ньому не клікає), Яндекс страхується від втрати прибутку, а ви - втрачаєте гроші, переплачуючи за дорогі кліки. Таким чином, уточнимо завдання - нам потрібно мінімум показів і максимум кліків, при цьому ми не знаємо і не можемо знати здебільшого запитів, з якими працюємо, у нас спостерігається явний дефіцит інформації.
Як же бути в такій ситуації?
В активі: у нас є інструменти для управління кількістю показів (оператори, мінус-слова), у нас є інструменти для розширення семантичного ядра (пошукові підказки через Key Collector або MOAB Suggest , Власна статистика сайту, статистика чужих сайтів через MOAB Pro )
У пасиві: ми не знаємо точного формулювання більшості запитів
Тепер ми підійшли до найцікавішого - покрокової схемою дій. Час теорій пройшов, настав час практики.
Крок 1
На першому етапі нам потрібно семантичне ядро, яке відрізняється максимальною статистичною достовірністю.
Що таке статистична достовірність?
Коли ви працюєте з великими даними, ви часто не можете (та це й не потрібно), обробити всі доступні дані. В цьому випадку ви берете якийсь статистично достовірний зріз даних, аналізуєте його, а потім використовуєте отримані дані, також, як якщо б проаналізували весь масив. Говорячи простою мовою, можна привести приклад соціологічних центрів - «Левада центру» або «ВЦИОМ»: при проведенні соцопитувань зазвичай опитується тільки 1600 людина, розподілених рівномірно по всій Росії, при цьому виявляється, що розподіл думок в серед всіх людей взагалі майже не відрізняється від розподілу думок всередині опитаної вибірки в 1600 чоловік.
Також зробимо і ми - на першому етапі постараємося отримати найбільш достовірну вибірку, до якої зможемо дотягнутися. Про джерела такої вибірки ми докладно писали тут . Зазначу, що і до цього дня найбільш повним і достовірним джерелом семантики є статистика сайту з багатим органічним або контекстним трафіком.
Отже, ми отримали вибірку. Візьмемо, для прикладу, вибірку за запитом «натяжні стелі» з бази MOAB Pro.
Вибірка з MOAB Pro - 391 045 запитів, для ознайомлення можна скачати файл з 2000 найбільш частотних запитів
Вибірка з MOAB Suggest - 102 166 запитів, ви можете завантажити повний файл
крок 2
Тільки на перший погляд вибірка здається нагромадженням хаотичних запитів, не пов'язаних між собою. Насправді, найпростіша кластеризація, виконувана за допомогою інструменту «Аналіз груп» в Key Collector виявляє розбиття ядра на абсолютно чіткі сегменти.
Зверніть увагу, що кластеризацию потрібно виконувати «За окремими словами» , Це вказується на панелі налаштувань аналізатора.
Подібний аналіз, наприклад, як це видно, на зазначеному скріншоті, виявляє зовсім чітку групу інформаційних запитів «розплавився» - все запити містять різні групи цього дієслова. Це показує нам, що існує сегмент реальних інтересів користувачів, згрупованих навколо проблеми розплавлення натяжної стелі.
Незважаючи на те, що ми, по суті, знаємо лише малу частину реальних запитів цього сегмента, ми можемо додати сам дієслово «розплавитися» в стоп-файл, що повністю заборонить покази по будь-яким варіацій цього запиту, тобто «відріже» трафік по всьому сегменту.
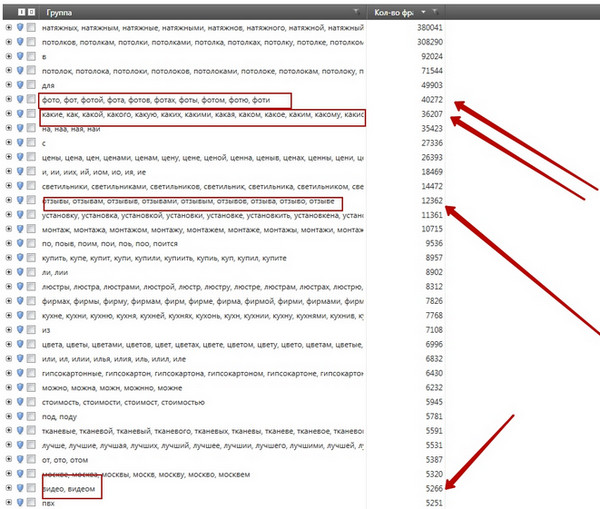
Подібну операцію мінусаціі сегмента можна провести і для більш популярних сегментів, наприклад:
Дивитися в повному розмірі
Очевидно, що такі сегменти, як «відгуки» або «відео» навряд чи дадуть високу конверсію в покупців, очевидно, що їх краще додати в стоп-слова. Зверніть увагу на цифри поруч з сегментами - ці цифри, фактично, означають кількість запитів всередині сегмента - наприклад, сегмент «фото» містить майже 40000 запитів, грубо кажучи, це близько 10% трафіку в усій тематиці.
А тепер уявіть - аналізуючи сегментацію, ми витратили всього 1-2 хвилини, щоб переглянути першу сторінку результатів. За цей час ми додали в стоп-файл чотири сегменти:
- відгуки
- які
- фото
- відео
Ці 4 сегмента сумарно містять близько 94 000 запитів, що становить, за грубою оцінкою, чверть трафіку в тематиці. Тобто, питання навіть не в кількості, а в якості мінус слів - можна придумати або запозичити в одного скільки завгодно мінус слів, але ось яке відношення вони матимуть до реального семантичному ядру?
Спробуємо розвинути цю ідею далі: адже якщо переглянути верхні 20% рядків в кластеризації і відзначити як стоп-слова «непотрібні» бізнесу сегменти, ми «відріжемо» за кількістю 90-95% "непотрібного" трафіку.
Якщо повернутися трохи назад, ми побачимо, для чого нам потрібен статистично достовірний масив - сегменти статистично достовірного масиву з дуже високою точністю копіюють реальний масив з безліччю невідомих нам запитів.
При цьому, незважаючи на те, що запити можуть бути сформульовані як завгодно, самі сегменти все одно залишаться такими ж - і при виконанні кластеризації і її подальшому аналізі, ми все одно «виловимо» і «відріжемо» більшу частину неефективних для бізнесу сегментів.
Таким чином, можна сформулювати кілька загальних правил:
- для мінусаціі нам потрібен максимально статистично достовірний файл, максимум запитів з підтвердженим трафіком - штучна семантика тут неефективна
- мінусація повинна виконуватися на основі кластеризації, при цьому, якщо вам потрібен дійсно точний і ефективний контекст, ви повинні переглянути хоча б верхні 20% рядків в кластерізаторе і виявити неефективні сегменти, склавши з них стоп-файл. Цей стоп файл буде досить великим, проте саме він дасть вам можливість на наступному етапі відмовитися від використання уточнюючих операторів - адже навіть якщо ви не знаєте всіх запитів, ви можете бути впевнені, що ваш стоп-файл стане надійним щитом, який захистить вас від « непотрібних »показів.
Іншими словами, у нас є два інструмент регулювання охоплення - стоп-файл і уточнюючі оператори. Володіючи статдостоверним масивом, ми по максимуму використовуємо мінус-слова, переносячи саме на них акцент в «очищенні» трафіку від сміття.
При цьому уточнюючі оператори ми використовуємо по мінімуму, що, в свою чергу, дає нам максимальне охоплення саме з невідомих нам запитам, які, по суті, є розширеннями від тих запитів, які ми зібрали.
В даному випадку доречно нагадати, що Директ розуміє форми слів «розплавитися» і «розплавився» - тобто, не важливо яку саме форму слова ви додасте в стоп-файл, проте «розплавлений» вже потрібно додавати окремо - частини мови воєдино Директ не пов'язує . Всі спецсимволи, крім точки, для Діректа рівнозначні пробілу - тобто, числове мінус-слово (наприклад, артикул) «49-53» буде розпізнано як два окремих мінус слова, розділені пропуском, в той час, як «49.53» буде розпізнано як єдине стоп-слово.
Також важливо згадати чисто технічний момент: найбільш зручним способом очистити сам по собі масив ключових фраз від сміття, щоб перейти до наступного етапу угруповання, є регулярні вирази, реалізовані в Key Collector, про які багато незаслужено забувають або просто не знають.
Отже, уявімо, що у вас є стоп-файл у форматі Діректа, який ви зібрали, аналізуючи кластери в частотному словнику:
- відгуки, - відео, безкоштовно, -Завантажити, ....-Київ, -астана, владивосток
Ви можете перетворити ці фрази в конструкцію виду:
відгук | відео | бесплатн | скачать | ...... | киев | АСТАН | владивосток
А потім додати отриману конструкцію в Key Collector на вкладці з неочищеним масивом .
В результаті в отриманій вибірці будуть всі фрази, які підходять під одне з умов, тобто містять або «відгук» або «відео» або «бесплатн», і так далі. Акуратніше треба бути з неоднозначними словами типу «ноги» - умова формату «ніг» забере під фільтр і «ногинск», і «ноггано», і «триноги», при цьому «ногинск» і «ноггано» можуть бути стоп-словами в конкретному контексті, а «триноги» - немає.
Перевага в тому, що можна, з одного боку, швидко прибрати з масиву всі непотрібні фрази, з іншого боку - ви можете застосовувати отримане регулярний вираз в подальшому до масивів схожої тематики, економлячи час на очистку від непотрібних запитів.
Як домогтися високого CTR з невідомих запитам?
Тепер уявімо, що ми відібрали величезний стоп-файл, благо тепер допустимий розмір стоп-файлу в Яндекс.Директі - 20 000 знаків. Таким чином, ми «відрізали» весь трафік з потенційно низькою конверсією - всі сегменти, маркерами яких є деякі характерні слова, додані в наш стоп-файл.
Однак, ми зробили тільки половину справи. Перед нами все ще стоїть питання - як домогтися ефективних показів не тільки і не стільки по тих запитах, які увійшли в наше семантичне ядро, але і по їх перекомбінація і розширенням.
Найбільш ефективний шлях - подальша робота з сегментацією. Спробуйте відволіктися від неефективного підходу «1 ключ = 1 оголошення». Уявіть, що одне оголошення - це один сегмент з «Аналізу груп» з прив'язаними до нього запитами. Давайте спробуємо уявити в чому плюси і мінуси такого підходу.
Візьмемо для прикладу сегмент «реставрація» . Уважний читач, звичайно, може відзначити, що в сегменті залишилися запити, які формально можна вважати «сміттєвими» - але і серйозну очистку ми не проводили для цього масиву - просто показали на невеликому прикладі, як це робиться на практиці. Тому умовно представимо, що всі запити всередині сегменти - цільові.
Отже, в сегменті «Реставрація» міститься 24 ключових запиту:
тканинні натяжні стелі реставрація
натяжні стелі реставрація ванн
реставрація натяжних стель
ремонт натяжних стель реставрація порізів
реставрація натяжної стелі
реставрація порізів натяжних стель
чи можлива реставрація натяжних стель
лоджії, балкони, натяжна стеля реставрація ванни
ремонт та реставрація натяжної стелі
ремонт та реставрація натяжних стель
ремонт натяжних стель реставрація порізів в Єкатеринбурзі
ремонт натяжних стель реставрація порізів в Уфі
ремонт натяжних стель реставрація порізів своїми силами
ремонт натяжних стель, реставрація порізів
реставрація натяжної стелі дірки
реставрація натяжної стелі петрозаводск
реставрація натяжної стелі після затопило
реставрація натяжної стелі після затопило, телефон фірм
реставрація натяжної стелі своїми руками
реставрація натяжної стелі своїми силами
реставрація натяжних стель ПВХ
реставрація натяжних стель телефони
реставрація розрізаного натяжної стелі
фірми з дрібного ремонту і реставрації натяжних стель
Цінність сегментів полягає не в конкретних фразах, а в тому, що вони дають нам знання про те - є ось така група інтересів користувачів. Значить, ми можемо створити релевантне групі оголошення:
Тема: Реставрація натяжних стель
Текст: Ремонт стель під ключ! Виїзд і оцінка безкоштовно.
Потім вивантажуємо оголошення в Директ, разом з наведеними вище ключами і запускаємо покази. Ключі, природно, вивантажуємо без операторів.
Що ж ми отримаємо в результаті?
По-перше, зверніть увагу на т.зв. «Базис» сегмента. Всі ключові слова сегмента включають в себе 3 слова - реставрація, натяжних, стель. Це означає, що оголошення буде генерувати покази тільки по тим запитам, які містять всі 3 слова одночасно + будь-які доповнення та розширення, про які ми не знаємо.
Тобто, цілком імовірно, що багато ключі сегмента не будуть генерувати показів в принципі. Велика частина показів доведеться на запит «реставрація натяжних стель», так як саме він буде залучати розширені покази по ключам формату «реставрація натяжних стель + розширення».
Одночасно з цим, ми не будемо залучати покази по непотрібним нам невідомим розширенням, за рахунок наявності якісного стоп-файлу. А що ж з клікабельністю по настільки потрібним нам «невідомим» запитам?
Погляньмо на видачу :
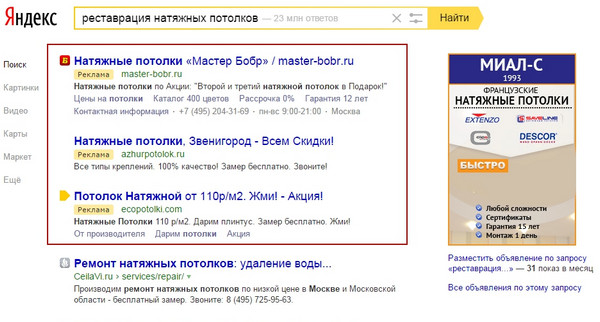
Рекламуючи за допомогою одного з ключових слів сегмента, в тому числі і по невідомому розширенню, ви отримаєте просто приголомшливий CTR: найбільш важливого для користувача слова «реставрація» немає ні в одному з оголошень Директа, але ж саме воно в заголовку оголошення та притягне його найбільшу увагу , причому на будь-якій позиції спецрозміщення.
Більш того, ви заберете трафік у органічної видачі:
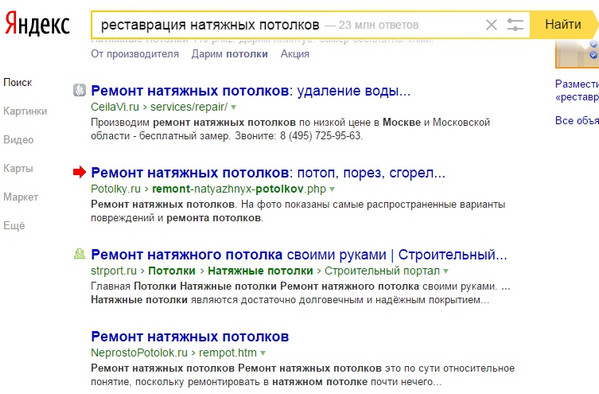
Жодного слова «реставрація» немає в заголовках органічної видачі та Діректа в самому конкурентному регіоні країни - в Москві, а в Ю Я в заголовках немає навіть синонимичного «ремонту»! Було б неприпустимим подарунком конкурентам не скористатися такою ситуацією - тим не менш, це стандартна ситуація для більшості низькочастотних видач.
Безсумнівно, що в таких умовах, ви зможете отримувати максимум трафіку навіть не з першої, а з будь-якої, самої дешевої позиції спецрозміщення. Пізніше ми обговоримо, як саме використовувати і звернути собі на благо цю ситуацію.
По-друге, зверніть увагу на те, як буде складено заголовок і текст. Тема копіює базис групи - три слова, що входять в усі ключі сегмента, займає 29 символів. Потім йде перше речення тексту, що складається з 24 символів. 24 + 29 = 53, тобто вкладаємося в правило « 56 символів ». На видачу на практиці отримуємо оголошення:
Тема: Реставрація натяжних стель - Ремонт стель під ключ!
Текст: Виїзд і оцінка безкоштовно.
У підсумку, при запиті будь-якого, нехай навіть перекомбініровать запиту в рамках даного сегмента, ми отримаємо як мінімум 4 підсвічених слова в даному заголовку:
- реставрація - 1 входження
- натяжних - 1 входження
- стель - 2 входження
Зверніть увагу, що в розширений заголовок не випадково потрапив також і «ремонт» - він занадто часто - аж 8 разів трапляється в ключових словах сегмента, на видачу по цьому запиту «ремонт» підсвічується в сніппеттах і розпізнається як синонім. Це важливий сигнал - значить, висока ймовірність його вживання разом з базисом групи, а значить - треба в такому випадку отримати вживання в заголовку, щоб підвищити кликабельность і за такими запитами.
Якісь із запитів в даній групі згенерують покази, якісь ні.
У будь-якому випадку, сумарна якість і кількість цільового трафіку з кампанії, зібраної в рамках такої архітектури, перевершить будь-які ваші очікування в порівнянні з кампаніями, зібраними в стандартній архітектурі «1 ключ = 1 оголошення». З досвіду клієнтів MOAB, яких ми консультували, в середньому вартість ліда після подібної пересборки кампаній падала в 3-4 рази.
Однак є дуже важливий момент: працюючи з випадковим масивом запитів, ми повинні весь час відслідковувати базис кожного оголошення. В даному випадку під базисом розуміється ключовий запит, який складається тільки з тих слів, які входять в кожне (!) Ключове слово оголошення.
В даному випадку, базис це - [реставрація натяжних стель]
Так вийшло, що даний ключ природним чином потрапив в групу «реставрація». Це призведе, в свою чергу до того, що при невідомому нам запиті користувача - [реставрація натяжних стель москва проспект Леніна] - наше оголошення буде показано на цей запит, так як даний ключ є розширенням від [реставрація натяжних стель].
Однак, давайте поглянемо на інший сегмент - [Коркові натяжні стелі]
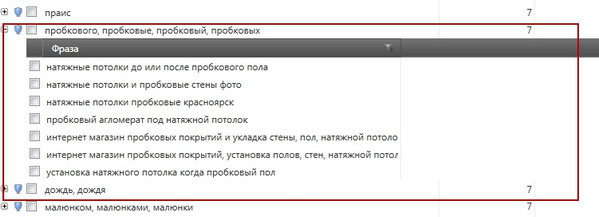
Дивитися в повному розмірі
Справа в тому, що коли ми працюємо з ядром, то в більшості випадків, базис сегмента природним шляхом виявляється серед ключів сегмента і генерує покази по розширеним варіантів запиту. Однак, якщо поглянути на скріншот, видно, що в даному сегменті базис [Коркові натяжні стелі] відсутня, тобто показу по невідомому запитом - [Коркові натяжні стелі москва] - не відбудеться.
В цьому випадку, цю ситуацію треба відстежити самостійно і додати в групу штучний, формально кажучи, ключ [пробкові натяжні стелі], щоб отримати покази по всіх невідомих запитам даного сегмента.
До слова, всім хто хоче дійсно серйозно попрацювати з управлінням контекстною рекламою на основі операторів, рекомендую ознайомиться з нашою статтею « Шість секретів контекстної реклами », Особливо - з пунктом 3, в якому розказано, які додаткові заходи можна вжити для зниження вартості показів по порівняно дорогим запитам з Wordstat, так, щоб при цьому зберегти покази по« невідомим »запитам.
Як гнучко регулювати вартість кліка на основі середньоринкових даних?
Отже, заключний етап створення кампанії - грамотне регулювання ставок. Давайте поглянемо на стандартний підхід «1 ключ = 1 оголошення» з точки зору ставок. Виходить, що всі рекламодавці працюють з Wordstat, забираючи звідти приблизно один і той же набір «комерційних» фраз. Після цього фрази з оператором «лапки» завантажуються в акаунт і включається кампанія. У підсумку маємо величезний набір рекламодавців, які конкурують за жорстко обмежений набір фраз все разом. Природно, це розігріває аукціон конкретно за цими фразами, в той час як конкуренція за «невідомим» запитам залишається порівняно «спокійною».
Однак залишимо теорію - сьогодні у нас є для вас ще кілька важливих практичних порад.
1. Працюйте з ринковою ціною на ваші ключові слова.
Як її дізнатися?
Дуже просто: додайте очищений масив фраз в Key Collector, а потім зніміть вартість кліка по кожній фразі .
У вікні виберіть наведене нижче
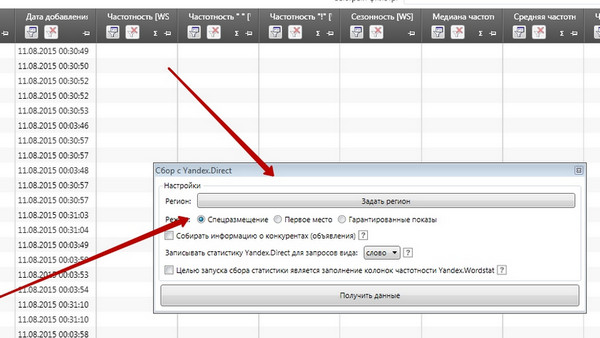
Дивитися в повному розмірі
В поле «Поставити регіон» обов'язково задайте регіон геотаргетинга, з яким ви працюєте. Після чого чекайте деякий час, а потім зверніться до інформації, отриманої в поле CPC YD:
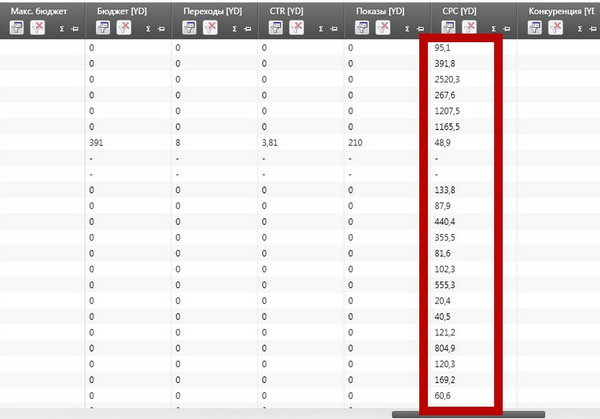
Дивитися в повному розмірі
Розрахуємо середню вартість кліка за отриманим масиву. Потім вибираємо «Середнє» та отримуємо результат:
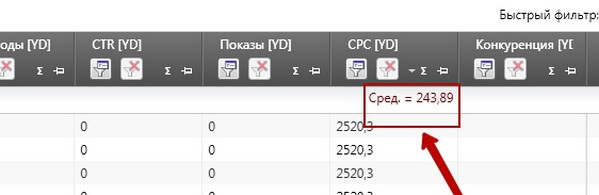
Дивитися в повному розмірі
Отримана цифра майже в 250 рублів - середня ринкова вартість кліка на основі «Прогнозу бюджету» Діректа. Для розрахунку прогнозних значень Директ, природно, бере середнє значення по системі, на практиці ваша вартість кліка в середньому буде набагато нижче.
Однак, отримуючи дане середнє значення і працюючи з великим масивом фраз, ми можемо хоча б приблизно заздалегідь зрозуміти, які фрази є свідомо переоціненими, а які - недооцінені.
Саме значення середньої ринкової вартості (або його похідні, наприклад, середня вартість * 0,50) ми рекомендуємо використовувати на першому етапі откруткі кампанії як максимальну ставку, що виставляється в Біддера. Потім ця ставка може бути скоригована з урахуванням фактичної ситуації по маржинальність і окупності контекстної реклами.
Як працювати з Біддера?
Ми працюємо з Біддера ДіректМенеджер і рекомендуємо його нашим партнерам. Серед переваг даного Біддера - в першу чергу величезний набір змінних, з яких можна писати власні стратегії і часта оновлюваність ставок (до 1 разу на 5 хвилин).
Для кампаній, створених за описаною вище архітектурі, ми використовуємо таку комбінацію стратегій:
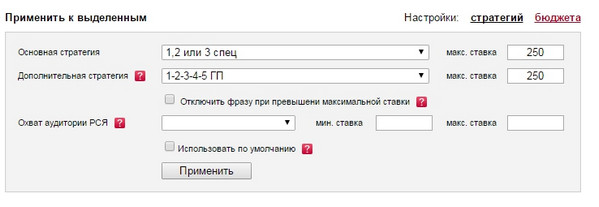
Ось текстовий вигляд основної стратегії:
якщо (1С менше 2С і 1С менше 3С) {
1С + 0.02
} Інакше якщо (2С менше 1С і 2С менше 3С) {
2С + 0.02
} Інакше {
3С + 0.02
}
Ось текстовий вигляд додаткової стратегії:
якщо (1М менше 2М і 1М менше 3М і 1М менше 4М і 1М менше 5М і 1М менше ГП) {
1М + 0.02
}
інакше якщо (2М менше 1М і 2М менше 3М і 2М менше 4М і 2М менше 5М і 2М менше ГП) {
2М + 0.02
}
інакше якщо (3М менше 1М і 3М менше 2М і 3М менше 4М і 3М менше 5М і 3М менше ГП) {
3М + 0.02
}
інакше якщо (4М менше 1М і 4М менше 2М і 4М менше 3М і 4М менше 5М і 4М менше ГП) {
4М + 0.02
}
інакше якщо (5М менше 1М і 5М менше 2М і 5М менше 3М і 5М менше 4М і 5М менше ГП) {
5М + 0.02
}
інакше {ДП + 0.02}
Що ж означають всі ці цифри на практиці?
Біддер раз в 5 хвилин звертається до API Директа і отримує ціни на всі позиції спецрозміщення по конкретній фразі. З трьох отриманих значень для нашої конкретної кампанії, оголошення та ключового слова Біддер вибирає найдешевшу позицію - неважливо, третя це позиція, друга або перша. Потім він порівнює вартість цієї найдешевшої позиції з максимальною ставкою.
Якщо максимальна ставка менша за вартість найдешевшої позиції спецрозміщення, то розрахунок повторюється вже для гарантії - Біддер вибирає найдешевшу позицію в гарантії. Якщо ж вартість найдешевшої позиції укладається в межа максимальної ставки (яка дорівнює середньоринкової вартості кліка по масиву), то Біддер починає боротися за позицію, додаючи 0.02 до вартості найдешевшої позиції, після чого ваше оголошення показується на потрібній нам позиції.
На завершення статті хотілося б, наскільки це можливо, полегшити складання рекламних кампаній нашим читачам, надавши в їх розпорядження готові списки мінус слів, доступні для скачування (стануть доступні після публікації статті на сайті 19 серпня 2015 р - прим. Редактора).
Наведені мінус слова зібрані на основі аналізу відповідних вибірок з бази MOAB. Наведено 200 найбільш часто зустрічаються мінус слів. Все мінус слова наведені в 3 форматах: в форматі регулярного виразу для Key Colletor, в форматі, який відразу можна вставити в стоп-файл в інтерфейсі кампанії Яндекс.Директу, а також в форматі, який використовується для імпорту стоп-слів в проект в програмі « МегаЛемма ».
Регіональні списки (міста) мінус-слів для Білорусії, Росії та Казахстану:
1. Банки
- кредит - формат Діректа , формат регулярного виразу , формат Мегалемма
- займ - формат Діректа , формат регулярного виразу , формат Мегалемма
- внесок - формат Діректа , формат регулярного виразу , формат Мегалемма
2.Недвіжімость
- оренда квартири - формат Діректа , формат регулярного виразу , формат Мегалемма
- нерухомість - формат Діректа , формат регулярного виразу , формат Мегалемма
- іпотека - формат Діректа , формат регулярного виразу , формат Мегалемма
3. Туризм
- тури - формат Діректа , формат регулярного виразу , формат Мегалемма
- путівки - формат Діректа , формат регулярного виразу , формат Мегалемма
4. Авто
- авто - формат Діректа , формат регулярного виразу , формат Мегалемма
5. SEO і контекст
- seo - формат Діректа , формат регулярного виразу , формат Мегалемма
- контекстна реклама - формат Діректа , формат регулярного виразу , формат Мегалемма
- директ - формат Діректа , формат регулярного виразу , формат Мегалемма
- просування сайту - формат Діректа , формат регулярного виразу , формат Мегалемма
6. Телефони
- samsung - формат Діректа , формат регулярного виразу , формат Мегалемма
- apple - формат Діректа , формат регулярного виразу , формат Мегалемма
7.Forex
- forex - формат Діректа , формат регулярного виразу , формат Мегалемма
8. Авіаквитки
- купити авіаквитки - формат Діректа , формат регулярного виразу , формат Мегалемма
9. Ноутбуки
- ноутбук - формат Діректа , формат регулярного виразу , формат Мегалемма
10. Списки регіонів
- Росія - формат Діректа , формат регулярного виразу , формат Мегалемма
- Білорусь - формат Діректа , формат регулярного виразу , формат Мегалемма
- Казахстан - формат Діректа , формат регулярного виразу , формат Мегалемма
Руйнування міфів: «Як зробити контекстну кампанію своїми руками?Тонка червона лінія: мінус слова або уточнюючі оператори?
Як же бути в такій ситуації?
Як гнучко регулювати вартість кліка на основі середньоринкових даних?
Руйнування міфів: «Як зробити контекстну кампанію своїми руками?
Проблема концепції: чому уточнюючі оператори забирають у вас клієнтів?
Виникає питання: який відсоток від відомих Яндексу тільки з Метрик ключових слів Яндекс віддає в Wordstat?
К рекламуватися за запитами, які ще не задані?
К отримувати максимум охоплення по потрібних запитах, надійно відсікаючи зайве?
Як відсікти все «некомерційні» запити, коли ми навіть не знаємо їх точного формулювання?