

Забойцы кліентаў: чаму удакладняючыя аператары забіваюць вашу лидогенерацию?
- Разбурэнне міфаў: «Як зрабіць кантэкстную кампанію сваімі рукамі?»
- Праблема канцэпцыі: чаму удакладняючыя аператары забіраюць у вас кліентаў?
- Тонкая чырвоная лінія: мінус слова ці удакладняючыя аператары?
- Як жа быць у такой сітуацыі?
- крок 1
- крок 2
- Як дабіцца высокага CTR па невядомых запытам?
- Як гнутка рэгуляваць кошт кліку на аснове среднерыночных дадзеных?
- Рэгіянальныя спісы (горада) мінус-слоў для Беларусі, Расіі і Казахстана:
- 2.Недвижимость
- 3. Турызм
- 4. Аўто
- 5. SEO і кантэкст
- 6. Тэлефоны
- 7.Forex
- 8. Авіябілеты
- 9. Ноўтбукі
- 10. Спісы рэгіёнаў
Калі вы - уладальнік бізнесу або практыкуючы спецыяліст па кантэкстнай рэкламе, то загаловак артыкула, верагодна, ужо парушыў ваша душэўны спакой. Калі так - то вы, верагодна, многае выпускаеце. Зрэшты, у вашых канкурэнтаў, хутчэй за ўсё, памылак не менш - поспех тут залежыць больш ад таго, хто хутчэй зрэагуе.
У дырэктыў, ды і ў кантэкстнай рэкламе ў цэлым, існуе мноства міфаў і памылак: ад самага папулярнага «Дырэкт не акупаецца», да вар'яцтва на прасунутай аналітыцы пры месячным бюджэце кампаніі ў 30000 рублёў. Сёння мы паспрабуем разабрацца з адным з гэтых міфаў, пад назвай «Як зрабіць кантэкстную кампанію сваімі рукамі» (бясплатна, без рэгістрацыі і СМС).
Разбурэнне міфаў: «Як зрабіць кантэкстную кампанію сваімі рукамі?»
Такім чынам, цяжка сказаць чаму так адбылося, але якія душаць большасць прадпрымальнікаў і профільных спецыялістаў працуюць па наступнай схеме:
1) Спарсим семантычнае ядро з Wordstat і трохі пачысцім яго пры дапамозе самых прымітыўных інструментаў
2) Створым кампанію, у якой 1 слова = 1 аб'яву
3) Дастасуем да ўсіх фразах аператар «двукоссі» ў фармаце «ключавое слова» ці «! Ключавое! Слова»
4) Запусцім кампанію
5) У гэтым пункце звычайна прынята пісаць што-небудзь пра Ліды, званкі ці проста пісаць «Профіт!». Аднак на практыцы, такая кампанія дае ў 4-5 разоў менш кліентаў, чым магла б, і гэта яшчэ ў тым выпадку, калі бізнес аказваецца ў стане акупіць атрымоўваны трафік.
Калі ў схеме, якая прыведзена вышэй, вы знайшлі знаёмыя вам рысы - чытайце далей.
Праблема канцэпцыі: чаму удакладняючыя аператары забіраюць у вас кліентаў?
Найбольш праблемны пункт прыведзенай вышэй распаўсюджанай схемы - гэта пункт 3: «Дастасуем да ўсіх фразах аператар« двукоссі »»
Давайце звернемся да лічбаў. Як вядома, год ад года сярэдняя даўжыня запыту толькі расце, пра гэта можна даведацца з публічна даступных даследаванняў Яндэкса:
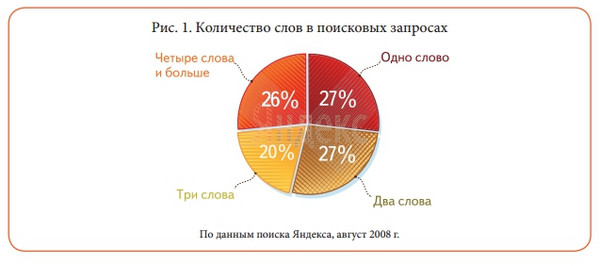
Даследаванняў 2008 года , Доля 4-Слоўнік 26%, сярэдняя даўжыня 2,5 словы супраць 1,2 словы ў 1997 годзе на момант запуску Яндэкса:
Глядзець у поўным памеры
Даследаванне 2009 года , Сярэдняя даўжыня 3 словы супраць 2,5 слова ў 2008 годзе. цытата:
«За год доля однословных запытаў на yandex.ru ўпала больш чым у чатыры разы, затое доля запытаў даўжынёй у чатыры і больш слоў стала больш амаль на 80%».
Глядзець у поўным памеры
Даследаванне 2011 года , Сярэдняя даўжыня 3,2-3,5 словы супраць 3 слоў у 2009 годзе. цытата:
«Мужчынскія запыты да Яндэксу трохі карацей жаночых - у сярэднім 3,2 і 3,5 словы адпаведна».

Глядзець у поўным памеры
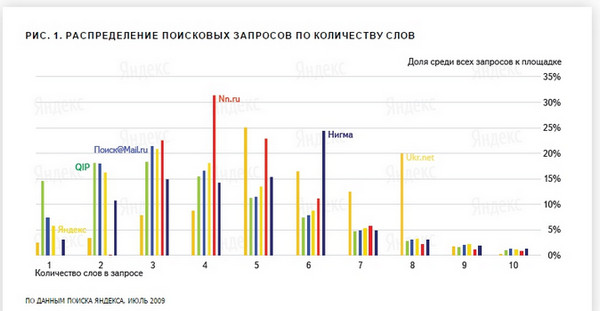
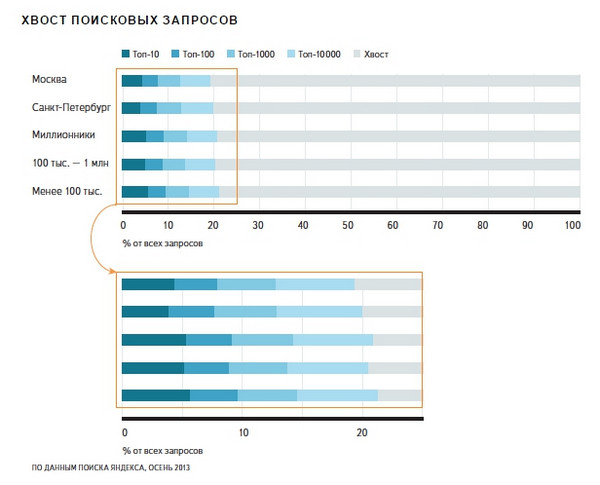
Даследаванне 2014 года ўжо не дае лічбаў па даўжыні запытаў, аднак паведамляе, што:
«Большая частка запытаў - у сярэднім каля 80% - не трапляе нават у топ-10000 (заўв. Аўт. - па трафіку) і складае так званы хвост пошукавых запытаў. У буйных гарадах гэты хвост трохі даўжэй - у мясцовых карыстальнікаў запыты разнастайней ».
Глядзець у поўным памеры
А цяпер, увага - менавіта ў гэтым месцы і адбываецца ўвесь фокус. Фокус - у наўмысным змаўчанні. Яндэкс сумленна кажа нам, што аснова пошуку - гэта нізкачашчынны хвост. Аднак гэты нізкачашчынны хвост немагчыма знайсці ў Wordstat, яго там папросту няма.
прыклад:
Wordstat - парсінга па запыце «мэбля» (май 2015) без ўказанні рэгіёну, з глыбінёй 6, атрымана 112.175 унікальных запытаў, з якіх у 98980 запытаў дакладная чашчыннасць адрозніваецца ад 0.
База MOAB - парсінга без ўказанні рэгіёну, дае 3 987 На старонку 908 запытаў, гэта значыць - амаль 4 мільёны ключавых слоў з пацьвердзіць трафік, выдатным ад нуля.
Розніца - у 40 разоў.
А цяпер сухія лічбы: мы атрымалі ключы з базы MOAB шляхам парсінга адкрытых лічыльнікаў Яндекс.Метрики, спарсив пры гэтым поўную гісторыю па 100 000 сайтаў з ~ 30 000 000 сайтаў, падлучаных да Метрыцы. Гэта значыць, спарсив дадзеныя толькі па 3% сайтаў, мы атрымалі ў 40 разоў больш ключавых слоў, чым ёсць у Wordstat. Узнікае пытанне: які адсотак ад вядомых Яндэксу толькі з метрыкай ключавых слоў Яндэкс аддае ў Wordstat?
На прыкладзе дадзенай выбаркі, можна падлічыць, што ўсяго толькі каля 0, 075%.
Вядома, дадзеная ацэнка вельмі грубіянская, аднак яна дапамагае зразумець наколькі разам непраўдзівыя публічныя крыніцы ключавых слоў - карыстаючыся толькі Wordstat, вы:
а) атрымліваеце статыстычна недакладную выбарку. Людзі задаюць значна больш пашыраных запытаў, чым можна ўбачыць у Wordstat. 7 і 8-Слоўнік могуць генераваць мноства лидов і дзесяткі пераходаў у дзень, пры гэтым іх дакладная чашчыннасць Wordstat будзе роўнай або блізкай да нуля за кошт затрымкі ў атрыманні дадзеных і / або некарэктным іх адлюстраванні
б) атрымліваеце найбольш пераацэненымі і канкурэнтныя запыты, даступныя ўсім іншым рэкламадаўцам
і, нарэшце, самае важнае:
в) у Wordstat вы атрымліваеце тыя самыя 20% найбольш частотных запытаў, якія фарміруюць «топ» тэматыкі. Затым звычайна фільтруецца смецце і запыты заключаюцца ў «двукоссі», абмяжоўваючы вобласць паказаў, каб дамагчыся большага CTR.
Але праблема ў тым, што сабраныя вамі ў Wordstat запыты нясуць толькі 10-15% ад агульнага трафіку тэматыкі. Гэта значыць, выкарыстоўваючы аператары, вы сваімі рукамі адмаўляецеся ад 85% тэматычнага трафіку тэматыкі, абмяжоўваючы ваш ахоп. Гэтыя 85% - гэта ультранизкочастотные запыты. Іх вельмі шмат, яны складаюцца з вялікай колькасці слоў і пастаянна перекомбинируются. На момант складання вашай кампаніі, многія з іх могуць быць наогул яшчэ не зададзены да пошуку - але сумарна усё гэта велізарная разнастайнасць рэдкіх запытаў сфармуе тыя самыя танныя Ліды ў пустых микронишах, пра якія ўсё так любяць казаць.
Такім чынам, мы патлумачылі праблему. Большая частка трафіку ў пошукавіках фармуецца запытамі, якіх няма ў Wordstat, часцяком іх няма наогул нідзе, паколькі яны часцяком яшчэ наогул не зададзены, альбо ж былі зададзены 1-2 разы. Такіх запытаў вельмі шмат, сумарна яны фармуюць гіганцкі трафік. Выкарыстанне ўдакладняючых аператараў, асабліва пры працы з найбольш ходкімі запытамі з Wordstat, дазваляе вам змагацца толькі за 10-15% ад рэальна магчымых паказаў.
Такім чынам, мы павінны адказаць на некалькі пытанняў:
- як рэкламавацца па вялікім аб'ёме НЧ-запытаў?
- як рэкламавацца па запытах, якія яшчэ не зададзены?
- як атрымліваць максімум ахопу па патрэбных запытах, надзейна адсякаючы лішняе? Як адсекчы ўсё «некамерцыйныя» запыты, калі мы нават не ведаем іх дакладнай фармулёўкі?
Менавіта пра гэта мы цяпер і пагаворым.
Тонкая чырвоная лінія: мінус слова ці удакладняючыя аператары?
Калі вы працуеце з дырэктыў, ваша задача, з фармальнага пункту гледжання, вельмі простая - па меншай меры, для пошукавага размяшчэння. У Яндэкса штодня ёсць нейкая сума паказаў, якую ён можа прадаць для пошукавага размяшчэння наогул у цэлым за суткі. Ваша аб'ява займае пэўную частку ад гэтай сумы, гэта значыць вы забіраеце на вашу аб'яву ў Яндэкса частка паказаў. У ідэале, вы павінны паказваць аб'яву толькі тым, хто здольны клікнуць па ім, так, каб колькасць клікаў было як мага бліжэй да колькасці паказаў. Калі з 100 паказаў, якія вы забралі, на вашу аб'яве клікнуць 1 раз, Яндэкс возьме з вас 10 даляраў за 1 клік, гэта значыць пры CTR 1% цана за клік для вас складзе 10 даляраў. Калі з 100 паказаў, якія вы забралі, на вашу аб'яве клікнуць 10 раз, Яндэкс возьме з вас 1 даляр за 1 клік, гэта значыць пры росце CTR ў 10 разоў да 10% цана за клік для вас знізіцца ў 10 разоў.
Важна тут тое, што Яндэкс у любым выпадку атрымае тыя ж самыя 10 даляраў, якія ён першапачаткова хацеў атрымаць, аддаючы вам 100 паказаў - гэта значыць, на самай справе Яндэкс прадае паказы, спакаваўшы гэта ў форму «платы за клік».
Гэта, вядома ж, вельмі грубая схема, аднак яе дастаткова, каб зразумець сэнс гульні: калі вы паказваеце вашу аб'яву тым, каму яно не патрэбнае (= тым, хто па ім не клікае), Яндэкс страхуецца ад страты прыбытку, а вы - губляеце грошы, пераплачваючы за дарагія клікі. Такім чынам, удакладнім задачу - нам трэба мінімум паказаў і максімум клікаў, пры гэтым мы не ведаем і не можам ведаць большай частцы запытаў, з якімі працуем, у нас назіраецца відавочны дэфіцыт інфармацыі.
Як жа быць у такой сітуацыі?
У актыве: у нас ёсць інструменты для кіравання колькасцю паказаў (аператары, мінус-слова), у нас ёсць інструменты для пашырэння семантычнага ядра (пошукавыя падказкі праз Key Collector або MOAB Suggest , Ўласная статыстыка сайта, статыстыка чужых сайтаў праз MOAB Pro )
У пасіве: мы не ведаем дакладнай фармулёўкі большасці запытаў
Цяпер мы падышлі да самага цікавага - пакрокавай схеме дзеянняў. Час тэорый прайшло, настаў час практыкі.
крок 1
На першым этапе нам трэба семантычнае ядро, якое адрозніваецца максімальнай статыстычнай пэўнасцю.
Што такое статыстычная пэўнасць?
Калі вы працуеце з вялікімі дадзенымі, вы часцяком не можаце (ды гэта і не трэба), апрацаваць усе даступныя дадзеныя. У гэтым выпадку вы бераце нейкі статыстычна дакладны зрэз дадзеных, аналізуеце яго, а затым карыстаецеся атрыманыя дадзеныя, таксама, як калі б прааналізавалі ўвесь масіў. Кажучы простай мовай, можна прывесці прыклад сацыялагічных цэнтраў - «Левада цэнтра» або «УЦДГМ»: пры правядзенні сацапытанняў звычайна апытваецца толькі 1600 чалавек, размеркаваных раўнамерна па ўсёй Расіі, пры гэтым аказваецца, што размеркаванне меркаванняў у сярод усіх людзей наогул амаль не адрозніваецца ад размеркавання меркаванняў ўнутры апытанай выбаркі ў 1600 чалавек.
Таксама паступім і мы - на першым этапе пастараемся атрымаць самую дакладную выбарку, да якой зможам дацягнуцца. Пра крыніцы такой выбаркі мы падрабязна пісалі тут . Адзначу, што і па гэты дзень найбольш поўным і пэўным крыніцай семантыкі з'яўляецца статыстыка сайта з багатым арганічным або кантэкстным трафікам.
Такім чынам, мы атрымалі выбарку. Возьмем, для прыкладу, выбарку па запыце «нацяжныя столі» з базы MOAB Pro.
Выбарка з MOAB Pro - 391 045 запытаў, для азнаямлення можна спампаваць файл з 2000 найбольш частотных запытаў
Выбарка з MOAB Suggest - 102 166 запытаў, вы можаце спампаваць поўны файл
крок 2
Толькі на першы погляд выбарка здаецца нагрувашчваннем хаатычных запытаў, не звязаных паміж сабой. На самай справе, найпростая кластарызацыя, выкананая пры дапамозе інструмента «Аналіз груп» у Key Collector выяўляе разбіццё ядра на зусім выразныя сегменты.
Звярніце ўвагу, што кластарызацыю трэба выконваць «Па асобных словах» , Гэта паказваецца на панэлі налад аналізатара.
Падобны аналіз, напрыклад, як гэта відаць, на паказаным скрыншоце, паказвае на цалкам выразную групу інфармацыйных запытаў «расплавіўся» - усе запыты ўтрымліваюць розныя групы гэтага дзеяслова. Гэта паказвае нам, што існуе сегмент рэальных інтарэсаў карыстальнікаў, группируемых вакол праблемы расплаўлення нацяжной столі.
Нягледзячы на тое, што мы, па сутнасці, ведаем толькі малую частку рэальных запытаў гэтага сегмента, мы можам дадаць сам дзеяслоў «расплавіцца» у стоп-файл, што цалкам забароніць паказы па любых варыяцыям гэтага запыту, гэта значыць «адрэжа» трафік па ўсім сегменту.
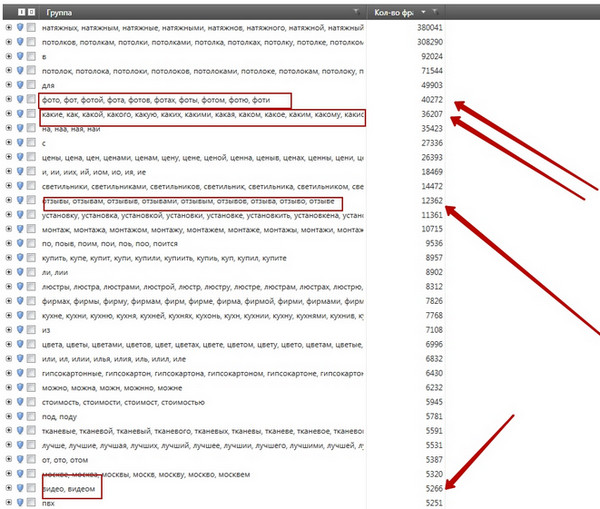
Падобную аперацыю минусации сегмента можна правесці і для больш папулярных сегментаў, напрыклад:
Глядзець у поўным памеры
Відавочна, што такія сегменты, як «водгукі» або «відэа» наўрад ці дадуць высокую канверсію ў пакупнікоў, відавочна, што іх лепш дадаць у стоп-словы. Звярніце ўвагу на лічбы побач з сегментамі - гэтыя лічбы, фактычна, азначаюць колькасць запытаў ўнутры сегмента - напрыклад, сегмент «фота» змяшчае амаль 40000 запытаў, груба кажучы, гэта каля 10% трафіку ва ўсёй тэматыцы.
А цяпер уявіце - аналізуючы сегментацыю, мы выдаткавалі ўсяго 1-2 хвіліны, каб праглядзець першую старонку вынікаў. За гэты час мы дадалі ў стоп-файл чатыры сегмента:
- водгукі
- якія
- фота
- відэа
Гэтыя 4 сегмента сумарна ўтрымліваюць каля 94 000 запытаў, што складае, пры грубай ацэнцы, чвэрць трафіку ў тэматыцы. Гэта значыць, пытанне нават не ў колькасці, а ў якасці мінус слоў - можна прыдумаць або запазычыць у аднаго колькі заўгодна мінус слоў, але вось якое дачыненне яны будуць мець да рэальнага семантычнага ядра?
Паспрабуем развіць гэтую ідэю далей: бо калі прагледзець верхнія 20% радкоў у кластарызацыі і адзначыць як стоп-словы «непатрэбныя» бізнэсу сегменты, мы «адрэжам» па колькасці 90-95% «непатрэбнага» трафіку.
Калі вярнуцца трохі назад, мы ўбачым, для чаго нам патрэбен статыстычна дакладны масіў - сегменты статыстычна дакладнага масіва з вельмі высокай дакладнасцю капіююць рэальны масіў з мноствам невядомых нам запытаў.
Пры гэтым, нягледзячы на тое, што запыты могуць быць сфармуляваны як заўгодна, самі сегменты ўсё роўна застануцца такімі ж - і пры выкананні кластарызацыі і яе наступным аналізе, мы ўсё роўна «вылавіць» і «адрэжам» большую частку неэфектыўных для бізнесу сегментаў.
Такім чынам, можна сфармуляваць некалькі агульных правілаў:
- для минусации нам патрэбен максімальна статыстычна дакладны файл, максімум запытаў з пацверджаным трафікам - штучная семантыка тут неэфектыўная
- минусация павінна выконвацца на аснове кластарызацыі, пры гэтым, калі вам патрэбен сапраўды дакладны і эфектыўны кантэкст, вы павінны праглядзець хоць бы верхнія 20% радкоў у кластеризаторе і выявіць неэфектыўныя сегменты, склаўшы з іх стоп-файл. Гэты стоп файл будзе дастаткова вялікім, аднак менавіта ён дасць вам магчымасць на наступным этапе адмовіцца ад выкарыстання ўдакладняючых аператараў - бо нават калі вы не ведаеце ўсіх запытаў, вы можаце быць упэўнены, што ваш стоп-файл стане надзейным шчытом, які абароніць вас ад « непатрэбных »паказаў.
Іншымі словамі, у нас ёсць два інструмент рэгулявання ахопу - стоп-файл і ўдакладняючыя аператары. Валодаючы статдостоверным масівам, мы па максімуму выкарыстоўваем мінус-словы, пераносячы менавіта на іх акцэнт у «ачыстцы» трафіку ад смецця.
Пры гэтым удакладняючыя аператары мы выкарыстоўваем па мінімуму, што, у сваю чаргу, дае нам максімальны ахоп як раз па невядомых нам запытам, якія, па сутнасці, з'яўляюцца пашырэннямі ад тых запытаў, якія мы сабралі.
У дадзеным выпадку дарэчы нагадаць, што Дірект разумее формы слоў «расплавіцца» і «расплавіўся» - гэта значыць, не важна якую менавіта форму слова вы дадасце ў стоп-файл, аднак «расплаўлены» ужо трэба дадаваць асобна - часціны мовы разам Дірект не звязвае . Усе спецзнакі, акрамя кропкі, для дырэктыў раўназначныя прабел - гэта значыць, лікавае мінус-слова (напрыклад, артыкул) «49-53» будзе распазнана як два асобных мінус словы, падзеленых прабелам, у той час, як «49.53» будзе распазнана як адзінае стоп-слова.
Таксама важна згадаць чыста тэхнічны момант: найбольш зручным спосабам ачысціць сам па сабе масіў ключавых фраз ад смецця, каб перайсці да наступнага этапу групоўкі, з'яўляюцца рэгулярныя выразы, рэалізаваныя ў Key Collector, пра якія шмат хто незаслужана забываюць або папросту не ведаюць.
Такім чынам, уявім, што ў вас ёсць стоп-файл у фармаце дырэктыў, які вы сабралі, аналізуючы кластары ў частотным слоўніку:
- водгукі, - відэа, -бесплатно, -скачать, ....-Кіяў, -астана, уладзівасток
Вы можаце ператварыць гэтыя фразы ў канструкцыю выгляду:
водгук | відэа | бясплатн | скачат | ...... | кіяў | Астаны | уладзівасток
А затым дадаць атрыманую канструкцыю ў Key Collector на ўкладцы з неабчышчаным масівам .
У выніку ў атрыманай выбарцы будуць усё фразы, якія падыходзяць пад адна з умоў, гэта значыць ўтрымліваюць або «водгук» або «відэа» або «бясплатн», і гэтак далей. Акуратней трэба быць з неадназначнымі словамі тыпу «ногі» - умова фармату «ног» забярэ пад фільтр і «Нагінскі», і «Ноггано», і «трыножкі», пры гэтым «Нагінскі» і «Ноггано» могуць з'яўляцца стоп-словамі ў канкрэтным кантэксце, а «трыножкі» - не.
Перавага ў тым, што можна, з аднаго боку, хутка прыбраць з масіва усе непатрэбныя фразы, з другога боку - вы можаце ўжываць атрыманае рэгулярны выраз у далейшым да масіваў падобнай тэматыкі, эканомячы час на ачыстку ад непатрэбных запытаў.
Як дабіцца высокага CTR па невядомых запытам?
Цяпер уявім, што мы адабралі велізарны стоп-файл, балазе цяпер дапушчальны памер стоп-файла ў Яндэкс.Дырэкт - 20 000 знакаў. Такім чынам, мы «адрэзалі» ўвесь трафік з патэнцыйна нізкай канверсіяй - усё сегменты, маркерамі якіх з'яўляюцца нейкія характэрныя словы, дададзеныя ў наш стоп-файл.
Аднак, мы зрабілі толькі палову справы. Перад намі ўсё яшчэ стаіць пытанне - як дамагчыся эфектыўных паказаў не толькі і не столькі па тых запытам, якія ўвайшлі ў наш семантычнае ядро, але і па іх перекомбинациям і пашырэння.
Найбольш эфектыўны шлях - далейшая праца з сегментацыю. Паспрабуйце адцягнуцца ад неэфектыўнага падыходу «1 ключ = 1 аб'яву». Уявіце, што адна аб'ява - гэта адзін сегмент з «Аналізу груп» з прывязанымі да яго запытамі. Давайце паспрабуем прадставіць у чым плюсы і мінусы такога падыходу.
Возьмем для прыкладу сегмент «рэстаўрацыя» . Уважлівы чытач, вядома, можа адзначыць, што ў сегменце засталіся запыты, якія фармальна можна лічыць «смеццевымі» - але і сур'ёзную ачыстку мы не праводзілі для гэтага масіва - проста паказалі на невялікім прыкладзе, як гэта робіцца на практыцы. Таму ўмоўна прадставім, што ўсе запыты ўнутры сегменты - мэтавыя.
Такім чынам, у сегменце «Рэстаўрацыя» ўтрымліваецца 24 ключавых запыту:
тканкавыя нацяжныя столі рэстаўрацыя
нацяжныя столі рэстаўрацыя ваннаў
рэстаўрацыя нацяжных столяў
рамонт нацяжных столяў рэстаўрацыя парэзаў
рэстаўрацыя нацяжной столі
рэстаўрацыя парэзаў нацяжных столяў
ці магчымая рэстаўрацыя нацяжных столяў
лоджыі, балконы, нацяжны столь рэстаўрацыя ванны
рамонт і рэстаўрацыя нацяжной столі
рамонт і рэстаўрацыя нацяжных столяў
рамонт нацяжных столяў рэстаўрацыя парэзаў ў Екацярынбургу
рамонт нацяжных столяў рэстаўрацыя парэзаў ў Уфе
рамонт нацяжных столяў рэстаўрацыя парэзаў сваімі сіламі
рамонт нацяжных столяў, рэстаўрацыя парэзаў
рэстаўрацыя нацяжной столі дзіркі
рэстаўрацыя нацяжной столі Петразаводск
рэстаўрацыя нацяжной столі пасля затапіла
рэстаўрацыя нацяжной столі пасля затапіла, тэлефон фірмаў
рэстаўрацыя нацяжной столі сваімі рукамі
рэстаўрацыя нацяжной столі сваімі сіламі
рэстаўрацыя нацяжных столяў пвх
рэстаўрацыя нацяжных столяў тэлефоны
рэстаўрацыя разрэзанага нацяжной столі
фірмы па дробным рамонце і рэстаўрацыі нацяжных столяў
Каштоўнасць сегментаў складаецца не ў канкрэтных фразах, а ў тым, што яны даюць нам веды пра тое - ёсць вось такая група інтарэсаў карыстальнікаў. Значыць, мы можам стварыць рэлевантнае групе аб'ява:
Загаловак: Рэстаўрацыя нацяжных столяў
Тэкст: Рамонт столяў пад ключ! Выезд і ацэнка бясплатна.
Затым выгружаем аб'яву ў дырэктыў, разам з прыведзенымі вышэй ключамі і запускаем паказы. Ключы, натуральна, выгружаем без аператараў.
Што ж мы атрымаем у выніку?
Па-першае, звярніце ўвагу на т.зв. «Базіс» сегмента. Усе ключавыя словы сегмента ўключаюць у сябе 3 словы - рэстаўрацыя, нацяжных, столяў. Гэта азначае, што аб'ява будзе генераваць паказы толькі па тым запытам, якія ўтрымліваюць усе 3 словы адначасова + якія-небудзь дапаўненні і пашырэння, пра якія мы не ведаем.
Гэта значыць, цалкам верагодна, што многія ключы сегмента не будуць генераваць паказаў у прынцыпе. Большая частка паказаў прыйдзецца на запыт «рэстаўрацыя нацяжных столяў», бо менавіта ён будзе прыцягваць пашыраныя паказы па ключах фармату «рэстаўрацыя нацяжных столяў + пашырэнне».
Адначасова з гэтым, мы не будзем прыцягваць паказы па непатрэбных нам невядомым пашырэння, за кошт наяўнасці якаснага стоп-файла. А што ж з клікабельнасць па гэтак патрэбным нам "невядомым" запытам?
зірнем на выдачу :
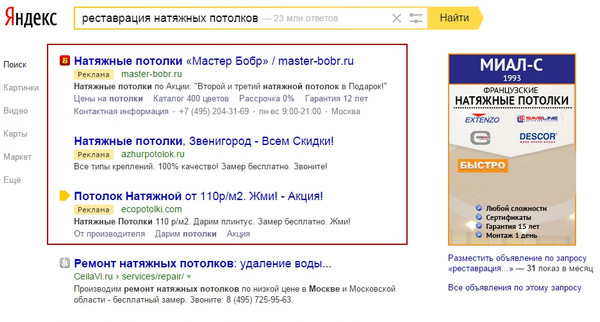
Рэкламуем па любым з ключавых слоў сегмента, у тым ліку і па невядомаму пашырэнню, вы атрымаеце проста надзвычайны CTR: найбольш важнага для карыстальніка словы «рэстаўрацыя» няма ні ў адным з аб'яў дырэктыў, а бо менавіта яно ў загалоўку аб'явы і прыцягне яго найбольшую ўвагу , прычым на любой пазіцыі спецразмещения.
Больш за тое, вы забярэце трафік ў арганічнай выдачы:

Ніводнага слова «рэстаўрацыя» няма ў загалоўках арганічнай выдачы і дырэктыў ў самым канкурэнтным рэгіёне краіны - у Маскве, а ў дырэктыў ў загалоўках нету нават сінанімічных «рамонту»! Было б недапушчальным падарункам канкурэнтам не скарыстацца такой сітуацыяй - тым не менш, гэта стандартная сітуацыя для большасці нізкачашчынных выдачаў.
Несумненна, што ў такіх умовах, вы зможаце атрымліваць максімум трафіку нават не з першай, а з любой, самай таннай пазіцыі спецразмещения. Пазней мы абмяркуем, як менавіта выкарыстоўваць і звярнуць сабе на карысць гэтую сітуацыю.
Па-другое, звярніце ўвагу на тое, як складзены загаловак і тэкст. Загаловак капіюе базіс групы - тры словы, якія ўваходзяць ва ўсе ключы сегмента, займае 29 знакаў. Затым ідзе першы сказ тэксту, якое складаецца з 24 знакаў. 24 + 29 = 53, гэта значыць ўкладваемся ў правіла « 56 сімвалаў ». На выдачы на практыцы атрымліваем аб'ява:
Загаловак: Рэстаўрацыя нацяжных столяў - Рамонт столяў пад ключ!
Тэкст: Выезд і ацэнка бясплатна.
У выніку, пры запыце любога, хай нават перекомбинированного запыту ў рамках дадзенага сегмента, мы атрымаем як мінімум 4 падсветленых слова ў дадзеным загалоўку:
- рэстаўрацыя - 1 ўваходжанне
- нацяжных - 1 ўваходжанне
- столяў - 2 ўваходжання
Звярніце ўвагу, што ў пашыраны загаловак не выпадкова патрапіў таксама і «рамонт» - ён занадта часта - аж 8 разоў трапляецца ў ключавых словах сегмента, на выдачы па гэтым запыце «рамонт» падсвятляецца ў сниппеттах і распазнаецца як сінонім. Гэта важны сігнал - значыць, высокая верагоднасць яго ўжывання разам з базісам групы, а значыць - трэба ў такім выпадку атрымаць ўжыванне ў загалоўку, каб павысіць клікабельнасць і па такіх запытам.
Нейкія з запытаў у дадзенай групе згенерыруюць паказы, якія-то няма.
У любым выпадку, сумарная якасць і колькасць мэтавага трафіку з кампаніі, сабранай у межах такой архітэктуры, перасягне любыя вашы чаканні ў параўнанні з кампаніямі, сабранымі ў стандартнай архітэктуры «1 ключ = 1 аб'яву». Па вопыце кліентаў MOAB, якіх мы кансультавалі, у сярэднім кошт Ліда пасля падобнай перабудовы кампаній падала ў 3-4 разы.
Аднак ёсць вельмі важны момант: працуючы са выпадковым масівам запытаў, мы павінны ўвесь час адсочваць базіс кожнага аб'явы. У дадзеным выпадку пад базісам разумеецца ключавой запыт, які складаецца толькі з тых слоў, якія ўваходзяць у кожнае (!) Ключавое слова аб'явы.
У дадзеным выпадку, базіс гэта - [рэстаўрацыя нацяжных столяў]
Так атрымалася, што дадзены ключ натуральным чынам трапіў у групу «рэстаўрацыя». Гэта прывядзе, у сваю чаргу да таго, што пры невядомым нам запыце карыстальніка - [рэстаўрацыя нацяжных столяў москва праспект Леніна] - наша аб'ява будзе паказана па гэтым запыце, бо дадзены ключ з'яўляецца пашырэннем ад [рэстаўрацыя нацяжных столяў].
Аднак, давайце зірнем на іншы сегмент - [Коркавыя нацяжныя столі]
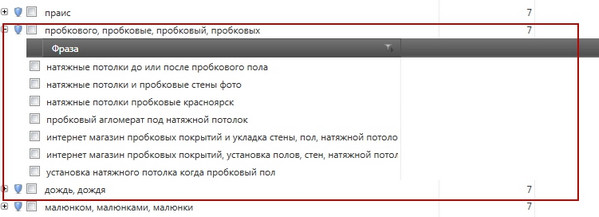
Глядзець у поўным памеры
Справа ў тым, што калі мы працуем з ядром, то ў большасці выпадкаў, базіс сегмента натуральным шляхам аказваецца сярод ключоў сегмента і генеруе паказы па пашыраным варыянтам запыту. Аднак, калі зірнуць на скрыншот, відаць, што ў дадзеным сегменце базіс [Коркавыя нацяжныя столі] адсутнічае, то ёсць паказу па невядомаму запыце - [Коркавыя нацяжныя столі москва] - не адбудзецца.
У гэтым выпадку, гэтую сітуацыю трэба адсачыць самастойна і дадаць у групу штучны, фармальна кажучы, ключ [коркавыя нацяжныя столі], каб атрымаць паказы па ўсіх невядомым запытам дадзенага сегмента.
Дарэчы, усім хто хоча сапраўды сур'ёзна папрацаваць з кіраваннем кантэкстнай рэкламай на аснове аператараў, рэкамендую азнаёміцца з нашым артыкулам « Шэсць сакрэтаў кантэкстнай рэкламы », Асабліва - з пунктам 3, у якім расказана, якія дадатковыя меры можна прыняць для зніжэння кошту паказаў па параўнальна дарагім запытам з Wordstat, так, каб пры гэтым захаваць паказы па« невядомым »запытам.
Як гнутка рэгуляваць кошт кліку на аснове среднерыночных дадзеных?
Такім чынам, заключны этап стварэння кампаніі - пісьменнае рэгуляванне ставак. Давайце зірнем на стандартны падыход «1 ключ = 1 аб'яву» з пункту гледжання ставак. Атрымліваецца, што ўсе рэкламадаўцы працуюць з Wordstat, забіраючы адтуль прыкладна адзін і той жа набор «камерцыйных» фраз. Пасля гэтага фразы з аператарам «двукоссі» загружаюцца ў рахунак і ўключаецца кампанія. У выніку маем велізарны набор рэкламадаўцаў, якія канкуруюць за жорстка абмежаваны набор фраз ўсе разам. Натуральна, гэта разагравае аўкцыён канкрэтна па гэтых фразах, у той час як канкурэнцыя па "невядомым" запытам застаецца параўнальна «спакойнай».
Аднак пакінем тэорыю - сёння ў нас ёсць для вас яшчэ некалькі важных практычных саветаў.
1. Працуйце з рынкавай цаной на вашыя ключавыя словы.
Як яе даведацца?
Вельмі проста: дадайце вычышчаны масіў фраз ў Key Collector, а затым зніміце кошт кліку па кожнай фразе .
У якое з'явілася акне абярыце наладзіць кампутар:
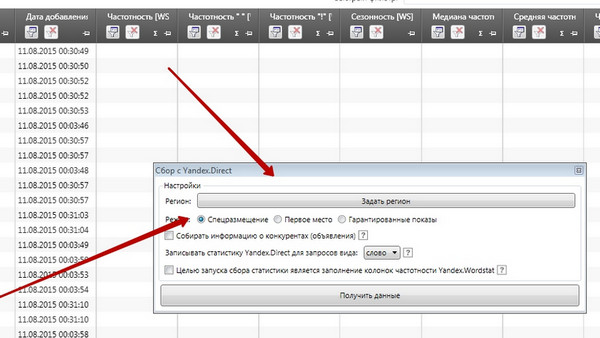
Глядзець у поўным памеры
У полі «Задаць рэгіён» абавязкова задайце рэгіён геотаргетинга, з якім вы працуеце. Пасля чаго чакайце некаторы час, а затым звярніцеся да інфармацыі, атрыманай у поле CPC YD:

Глядзець у поўным памеры
разлічым сярэдні кошт кліка па атрыманаму масіву. Затым выбіраем «Сярэдні» і атрымліваем вынік:
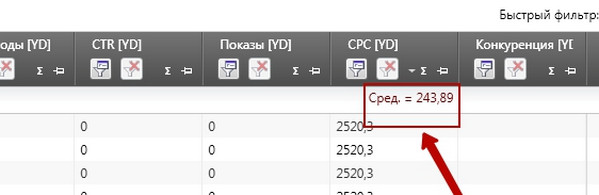
Глядзець у поўным памеры
Атрыманая лічба амаль у 250 рублёў - среднерыночных кошт кліку на аснове «Прагнозу бюджэту» дырэктыў. Для разліку прагнозных значэнняў Дірект, натуральна, бярэ сярэдняе значэнне па сістэме, на практыцы ваша кошт кліку ў сярэднім будзе значна ніжэй.
Аднак, атрымліваючы дадзенае сярэдняе значэнне і працуючы з вялікім масівам фраз, мы можам хаця б прыкладна загадзя зразумець, якія фразы з'яўляюцца заведама пераацэненымі, а якія - недаацэненыя.
Менавіта значэнне сярэдняй рынкавай кошту (або яго вытворныя, напрыклад, сярэдні кошт * 0,50) мы рэкамендуем выкарыстоўваць на першым этапе адкруткі кампаніі як максімальную стаўку, выстаўляюць у биддере. Затым гэтая стаўка можа быць скарэкціравана з улікам фактычнай сітуацыі па маржынальнасць і акупнасці кантэкстнай рэкламы.
Як працаваць з биддерами?
Мы працуем з биддером ДиректМенеджер і рэкамендуем яго нашым партнёрам. Сярод пераваг дадзенага биддера - у першую чаргу велізарны набор зменных, з якіх можна пісаць уласныя стратэгіі і частая обновляемость ставак (да 1 разу ў 5 хвілін).
Для кампаній, створаных па апісанай вышэй архітэктуры, мы выкарыстоўваем наступную камбінацыю стратэгій:
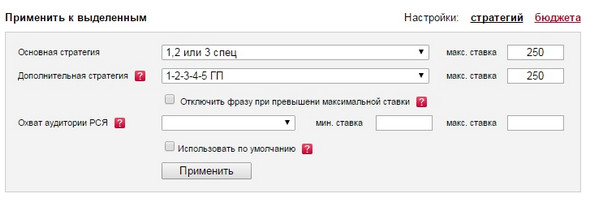
Вось тэкставы выгляд асноўнай стратэгіі:
калі (1С менш 2С і 1С менш 3С) {
1С + 0.02
} Інакш калі (2С менш 1С і 2С менш 3С) {
2С + 0.02
} Інакш {
3С + 0.02
}
Вось тэкставы выгляд дадатковай стратэгіі:
калі (1М менш 2М і 1М менш 3М і 1М менш 4М і 1М менш 5М і 1М менш ГП) {
1М + 0.02
}
інакш калі (2М менш 1М і 2М менш 3М і 2М менш 4М і 2М менш 5М і 2М менш ГП) {
2М + 0.02
}
інакш калі (3М менш 1М і 3М менш 2М і 3М менш 4М і 3М менш 5М і 3М менш ГП) {
3М + 0.02
}
інакш калі (4М менш 1М і 4М менш 2М і 4М менш 3М і 4М менш 5М і 4М менш ГП) {
4М + 0.02
}
інакш калі (5М менш 1М і 5М менш 2М і 5М менш 3М і 5М менш 4М і 5М менш ГП) {
5М + 0.02
}
інакш {ГП + 0.02}
Што ж азначаюць усе гэтыя лічбы на практыцы?
Биддер раз у 5 хвілін звяртаецца да API дырэктыў і атрымлівае цэны на ўсе пазіцыі спецразмещения па канкрэтнай фразе. З трох атрыманых значэнняў для нашай канкрэтнай кампаніі, аб'явы і ключавога слова биддер выбірае самую танную пазіцыю - няважна, трэцяя гэта пазіцыя, другая або першая. Затым ён параўноўвае кошт гэтай самай таннай пазіцыі з максімальнай стаўкай.
Калі максімальная стаўка менш кошту самай таннай пазіцыі спецразмещения, то разлік паўтараецца ўжо для гарантыі - биддер выбірае самую танную пазіцыю ў гарантыі. Калі ж кошт самай таннай пазіцыі ўкладаецца ў мяжа максімальнай стаўкі (якая роўная среднерыночной кошту кліку па масіве), то биддер пачынае змагацца за пазіцыю, дадаючы 0.02 да кошту самай таннай пазіцыі, пасля чаго ваша аб'ява паказваецца на патрэбнай нам пазіцыі.
У завяршэнне артыкула хацелася б, наколькі гэта магчыма, палегчыць складанне рэкламных кампаній нашым чытачам, падаўшы ў іх распараджэнне гатовыя спісы мінус слоў, даступныя для запампоўкі (стануць даступныя пасля публікацыі артыкула на сайце 19 жніўня 2015 г - заўв. Рэдактара).
Прыведзеныя мінус словы сабраны на аснове аналізу адпаведных выбарак з базы MOAB. Прыведзены 200 найбольш часта сустракаемых мінус слоў. Усе мінус словы прыведзены ў 3 фарматах: назваў паведамленняў для Key Colletor, у фармаце, які адразу ж можна ўставіць у стоп-файл у інтэрфейсе кампаніі Яндэкс.Дырэкт, а таксама ў фармаце, які выкарыстоўваецца для імпарту стоп-слоў у праект у праграме « МегаЛемма ».
Рэгіянальныя спісы (горада) мінус-слоў для Беларусі, Расіі і Казахстана:
1. Банкі
- крэдыт - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- пазыку - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- уклад - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
2.Недвижимость
- арэнда кватэры - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- нерухомасць - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- іпатэка - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
3. Турызм
- туры - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- пуцёўкі - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
4. Аўто
- аўто - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
5. SEO і кантэкст
- seo - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- кантэкстная рэклама - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- дырэктарка - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- прасоўванне сайта - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
6. Тэлефоны
- samsung - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- apple - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
7.Forex
- forex - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
8. Авіябілеты
- купіць авіябілеты - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
9. Ноўтбукі
- ноўтбук - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
10. Спісы рэгіёнаў
- Расія - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- Беларусь - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
- Казахстан - фармат дырэктыў , фармат назваў паведамленняў , фармат Мегалемма
Разбурэнне міфаў: «Як зрабіць кантэкстную кампанію сваімі рукамі?Тонкая чырвоная лінія: мінус слова ці удакладняючыя аператары?
Як жа быць у такой сітуацыі?
Як гнутка рэгуляваць кошт кліку на аснове среднерыночных дадзеных?
Разбурэнне міфаў: «Як зрабіць кантэкстную кампанію сваімі рукамі?
Праблема канцэпцыі: чаму удакладняючыя аператары забіраюць у вас кліентаў?
Узнікае пытанне: які адсотак ад вядомых Яндэксу толькі з метрыкай ключавых слоў Яндэкс аддае ў Wordstat?
К рэкламавацца па запытах, якія яшчэ не зададзены?
К атрымліваць максімум ахопу па патрэбных запытах, надзейна адсякаючы лішняе?
Як адсекчы ўсё «некамерцыйныя» запыты, калі мы нават не ведаем іх дакладнай фармулёўкі?