

Збір семантичного ядра для Діректа c покроковою інструкцією
- 1-ий крок. Збір маркерних слів для парсинга в Яндекс WordStat
- Чи треба платні сервіси і програми для збору семантичного ядра?
- 2-ий крок. Збір ключових фраз в Яндекс WordStat
- Збір ключових фраз конкурентів і бази
- Збір пошукових підказок
- Друга ітерація збору фраз для семантичного ядра
- Повторюся для початківців
- 3-ий крок. Видаляємо нецільові фрази
- Ділимо всі слова на: цільові / нецільові / сумніваюся
- Резюмую статтю
Зібравши повне семантичне ядро, ви завжди отримаєте конкурентну перевагу за рахунок більшого охоплення аудиторії і, отже, більше замовлень, покупок, лидов.
У цій публікації я постарався викласти весь процес початкового збору ключових фраз - сервіси, програми, принципи пошуку і роботи з отриманими даними. А так же, описаний спосіб складання базового списку мінус слів (на основі зібраного семантичного ядра), який виключить 95% всіх нецільових показів!
Спосіб збору універсальний і підійде не тільки для рекламної кампанії в Яндекс Директ, але і для формування повноцінної семантики для пошукового просування (SEO). Одне лише відмінність - збираючи семантичне ядро для контекстної реклами, зазвичай не йдуть так глибоко в НЧ фрази. А методи фільтрації і складання списку мінус слів - однаковий.
1-ий крок. Збір маркерних слів для парсинга в Яндекс WordStat
Статтю пишу на основі однієї з останніх моїх робіт - лижне спорядження, техніка катання і т.д.
Для пошуку маркерних слів використовуємо:
- Сам сайт, його розділи з товарами або послугами;
- Сайти конкурентів. Аналізуємо зовні по розділах і послуг, так і за допомогою сервісів - megaindex, key.so і тому подібних;
- Сервіси синонімів;
- Права і ліва колонка в Яндекс WordStat, блок «з таким твердженням шукають» під пошуковою видачею.
Маркерні слова / словосполучення - це тільки напрямки для подальшого вивчення, «копання» вглиб, так би мовити. Якщо в список вже додали фразу - «вибір лиж», то не треба додавати вкладену «вибір гірських лиж». Всі вкладені фрази будуть знайдені після парсинга в Key Collector.
Головне завдання - зібрати максимум маркерних слів (напрямків), перевірити синоніми, сленгові слова і сформувати загальний список, за яким будемо «копати» далі.
Формувати зручно в візуальному вигляді, наприклад в MindMap і виглядає ось так:
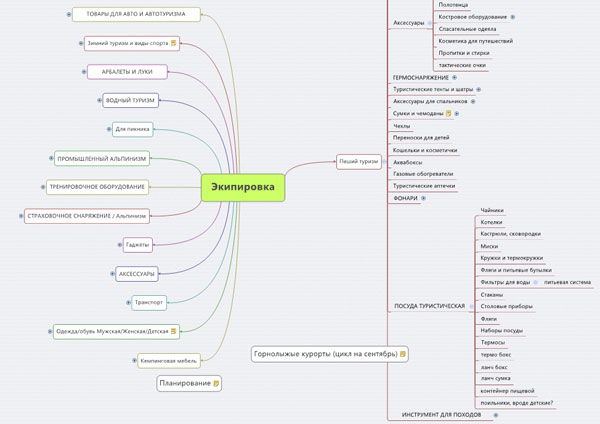
На скріншоті відкрита тільки одна гілка, щоб зображення було осудної розміру.
Величезна користь від такої візуалізації, особисто для мене, що якщо розкрити всі напрямки, відразу розумієш, що багатозадачність треба вимикати і працювати тільки з одним розділом, а не відразу з усіма. А то з послідовністю дій іноді виникають проблеми.
Важливо: Для швидкої обробки та збереження ключових слів в Wordstat, спробуйте безкоштовне розширення для браузерів - Yandex Wordstat Assistant. За допомогою нього можна швидко переносити необхідні ключові фрази в семантичне ядро.
У моєму випадку все просто, так як категорія інтересів одна - лижі. Тому не знадобилася така масштабна опрацювання:
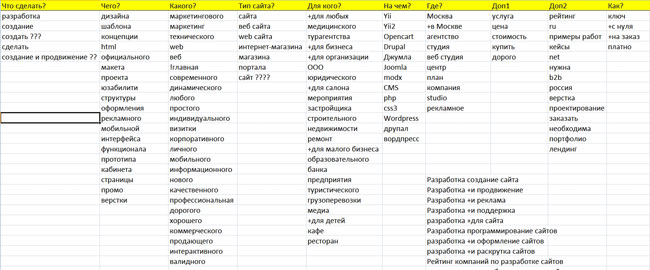
Таблиця з питаннями зручна для великих проектів. Не знаю, як її назвати професійно, але через такі питання, можна істотно розширити семантичне ядро, знайти нові ІНТЕНТ, про існування яких навіть не підозрював на початку.
Зібрані фрази перемножуються, а потім перевіряються на частотність в Wordstat. Частотні фрази додаються для подальшого вивчення.
Интент - це те, заради чого користувач вводить запит в пошукову систему. Можна сказати його «біль». Набір з ключових фраз може об'єднуватися по одному ІНТЕНТ, тобто бути викликаним одним мотивом, хоча при цьому написання і набір слів можуть відрізнятися.
Чи треба платні сервіси і програми для збору семантичного ядра?
Я використовую програму Кей колектор і все нижче описані дії проводжу в ньому. Якщо її немає, то зібрати повне ядро навряд чи вийде. Ви зможете, звичайно, вручну «походити» по Wordstat, розширення Wordstat Assistant в цьому сильно допоможе, взяти ще фрази з безкоштовних баз, на кшталт Букварікса. Але це все буде мала частина того, що дійсно можна зібрати.
У деяких ситуаціях цього достатньо, хоча я прихильник створення максимально повної семантики, особливо якщо тематика сайту невелика і тематичного трафіку мало. У таких випадках доцільно зібрати все, щоб максимально охопити свою нішу.
Якщо у вас один сайт, то вигідніше буде замовити послугу збору семантичного ядра на аутсорс. Заплатіть 3-5 тисяч рублів, але здобудете повну ядро з максимум ключових фраз, без необхідності купувати софт, оплачувати послуги і так далі.
Для Яндекс Директ ключові фрази в Key Collector збираю рідко, тільки коли великі рекламні кампанії, багато напрямків ... Для маленьких і середніх ніш досить Wordstat і опрацювання синонімів.
Знову ж таки, якщо передбачається створення рекламних кампаній для одного виду діяльності, і ви самі в ньому добре розбираєтеся, то зовсім не обов'язково витрачати гроші на сервіси і переглядати фрази і оголошення конкурентів.
Найчастіше діректологі погано розбираються в об'єкті реклами, і якщо ви рекламуєте ваш товар / послугу, то ви апріорі підберете правильні ключові фрази і кращі оголошення, які торкнуться необхідні струни вашої цільової аудиторії. Вам тільки треба розібратися в деяких тонкощах і послідовності роботи. Що я і постараюся докладно описати в цьому циклі статей.
2-ий крок. Збір ключових фраз в Яндекс WordStat
Зібрані маркерні слова пропускаємо через ліву колонку Wordstat  в Key Collector.
в Key Collector.
Для економії часу великі напрямки можна розбивати ось так ялинкою:

Більше семи слова WordStat не показує, тому в подібних запитах тільки семи немов шаблон.
Вордстат дає можливість переглянути лише 2000 вкладених фраз. Це 40 сторінок. Якщо перегорнути до 40-ій сторінці по фразі «лижі», то побачите, що список закінчується на вираженні з частотністю 62 показу. Для повного семантичного ядра цього буде мало, так як далі ще може бути кілька сотень низькочастотних фраз, які можуть приносити додатковий трафік.
Метод «ялинкою» дозволить скоротити час і не проводити повторну ітерацію парсинга отриманих ключових фраз після першого збору. Key Collector візьме все фрази з Wordstat з даного маркерні слову, аж до частотності в 1, не обмежуючись стандартними двома тисячами.
Збір ключових фраз конкурентів і бази
Використовуємо сервіс megaindex, key.so або serpstat.com. Бажано опрацювати 5-10 прямих конкурентів. З безкоштовних баз, можу порадити Букварікс .
Спостереження: якщо спочатку добре опрацьовані маркерні слова, синоніми, сленгові вислови, то Wordstat дає 70-80% пошукових запитів, а що залишилися добираються від конкурентів і букварікса.
Ці фрази не варто заважати з усіма, а додавати краще в окрему групу в кей колекторі.
Зверніть увагу, щоб при додаванні стояла галочка «Не додавати фразу, якщо вона є в будь-якій іншій групі»:
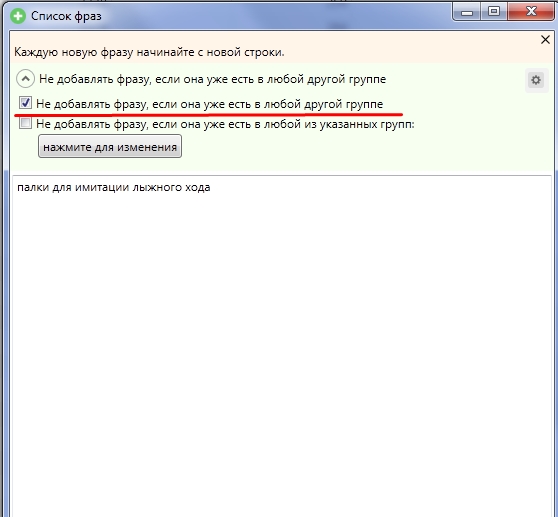
Цим обмеженням неприпустимий додавання дублюючих фраз в загальне семантичне ядро.
Букварікс - окрема історія. Дуже багато неявних дублів, запити розрізняються лише перестановкою слів. Знаходить багато фраз, але 70-80% з них не підійдуть нам. Додаю в окрему групу, але не вичищаю і не працюю з нею, а буду жадати цікаві для мене фрази пошуком, щоб подивитися, чи можна чим доповнити основну семантику з нього чи ні.
Збір пошукових підказок
Як тільки зібрали всі фрази в WordStat і конкурентів, слід об'єднати їх в мульти-групи 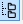 , Впорядкувати за базовою частотності (зазвичай від 100, або від 50 якщо ніша невелика) і вибрати цільові фрази для збору пошукових підказок по ним:
, Впорядкувати за базовою частотності (зазвичай від 100, або від 50 якщо ніша невелика) і вибрати цільові фрази для збору пошукових підказок по ним:
Друга ітерація збору фраз для семантичного ядра
На даному етапі зібрано майже все :). Для повноцінного ядра потрібно заглянути ще глибше і подивитися вкладені фрази для знайдених фраз в ході вищеописаних дій.
Для фраз, зібраних методом «ялинки» не треба проводити повторну ітерацію збору, а ось для запитів знайдених у конкурентів, обраних в букваріксе і пошукових підказок - варто.
Для повторної ітерації я сортую зібрані фрази по базовій частотності і вибираю цільові (так як ми ще не чистили стоп словами, не варто виділяти все підряд) до значення частотності в 100 одиниць. Заново запускаю по ним пакетний збір з лівої колонки Yandex WordStat .
Важливо: не заважайте все повторні збори разом, створюйте окремі групи для конкурентів, букварікса, основним ядра зібраному за маркерними словами, парсинг по другій ітерації і так далі. Чим докладніше ви роздробити в моменті збору семантики, тим простіше її буде чистити від нецільових фраз. Об'єднати завжди встигнете!
Повторюся для початківців
Такий глибокий збір необхідний в першу чергу для пошукового просування і для створення рекламних кампаній в Google Adwords, так як там ціна за клік вкладених ключових фраз не відрізняється від батьківської, на відміну від Яндекс Директ. Детальніше з ціноутворенням в системах контекстної реклами розберемося в наступних публікаціях.
Суть: для Діректа не обов'язково збирати ВСІ фрази в тематиці, для Adwords і SEO - бажано.
3-ий крок. Видаляємо нецільові фрази
На даному етапі треба видалити явно не цільові запити. Виконати це можна за допомогою універсальних стоп-слів. Я збираю їх в цьому файлі на Google Docs . Якщо у вас є власна база універсальних стоп слів, надішліть мені на пошту [email protected], я їх розміщу в цій таблиці, всім читачам на користь.
Ділимо всі слова на: цільові / нецільові / сумніваюся
Цей крок потрібен для створення загального списку мінус фраз, який можна використовувати відразу на всю рекламну кампанію і для чищення всієї семантики від нецільових пошукових запитів.
На виході отримуємо список з цільових і стоп слів за допомогою яких ми будемо чистити і перевіряти семантичне ядро.
Я прихильник параноїдального способу 🙂, який займає багато часу, але здатний виключити 95% всіх нецільових ключових фраз.
З досвіду скажу, чим якісніше опрацьований список мінус слів і фраз, тим менше в Яндекс Директ проскакують нецільового покази та покази по синонімів, які так любить додавати пошуковик для кампаній новачків, які не приділяють належної уваги цій процесу.
У вас буде найчистіше трафік, так як ми всі унікальні слова в семантиці перевірили в ручному режимі і визначили їх належність.
Алгоритм дій:
1. Вивантажуємо весь список ключових фраз в notepad.
2. Перетворюємо фрази в список слів. Їх буде багато, якщо брати мій приклад з семантикою під лижі, то близько 60 тисяч.
Приклад автоматичної заміни пробілу на «перенесення рядка» в notepad:
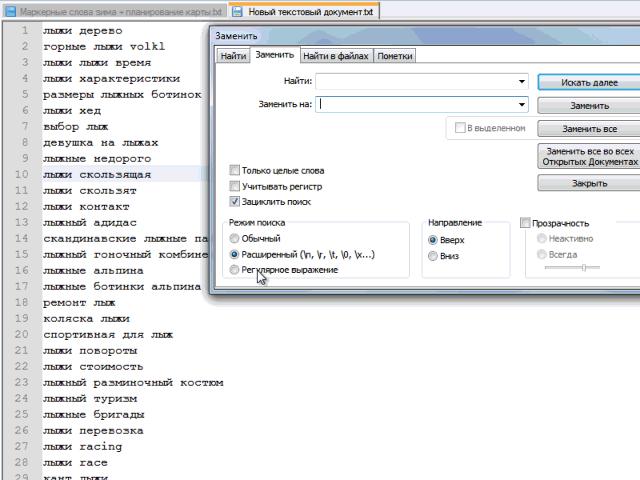
Цей крок деякі роблять в Word, ще якимись програмними засобами. Я для себе вибрав блокнот notepad. Головний плюс - мінімум дій для отримання бажаного результату.
3. Копіюємо все слова в Excel і видаляємо дублі:

Після видалення дублів, залишається близько 15-20% слів від загальної кількості.
Отримано список усіх унікальних слів в нашій семантиці. Далі кожне слово я проходжу з питанням: цільове / нецільове / сумніваюся. У слів, які явно цільові, ставлю 1 в сусідній комірці, у сумнівається 2, у мінус слів нічого не ставлю, так як їх буде найбільше.
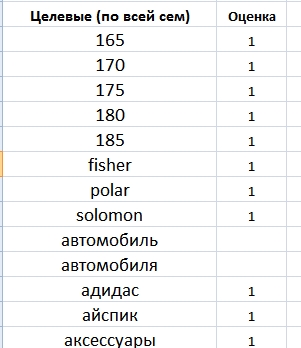
Всі ті, хто сумнівається слова перевіряю на конкретних пошукових фразах в семантичному ядрі (швидкий пошук кей колектора).
На виході отримуємо список цільових слів і мінус-слів. Після чого, можна відпочити і спробувати осмислити весь процес і зрозуміти описану послідовність.
Резюмую статтю
Використовую слово ітерація, щоб були зрозумілі проробляються дії. А то слово «збір» загальне і легко заплутатися, особливо новачкові.
Зараз ось задумався. Напевно даремно я об'єднав опис процесу збору семантики для SEO і Діректа. За великим рахунком, другий крок c поглибленим збором всіх фраз, для контексту не потрібен. Нам потрібні тільки ВЧ і СЧ фрази (частотність від 100 і вище, але залежить від тематики) і самі цільові НЧ.
У будь-якому випадку, пункти під номером 1 і 3 абсолютно однакові для обох видів робіт.
У наступних публікаціях ми почнемо групувати і сегментувати ключові фрази, а так само вичищати семантику від нецільових фраз, неявних дублів і всього того сміття, якого приблизно 70-80% від зібраного на даному етапі.
Підписуйтесь на оновлення блогу в Твіттері , Або по Email (форма в сайдбарі). Один раз в два тижні я проводжу розсилку про нові публікації. До скорого!
Чи треба платні сервіси і програми для збору семантичного ядра?