

JavaScript SEO - Как Google Crawl JavaScript «SEOPressor - плагин для WordPress SEO
- Googlebot
- Кофеин
- Процесс сканирования и индексации для веб-страницы на основе JavaScript отличается
- Так что же происходит, когда поисковая система достигает ваших обычных страниц, не использующих Java-скрипт,...
- Теперь вот что происходит, когда робот Google достигает вашей веб-страницы JavaScript.
- Что происходит, когда Google с возможностями рендеринга достигает ваших веб-страниц на основе JavaScript.
- Подвести итоги…

В SEO мы всегда смотрим на ранги и SERP, но нам также нужно знать процесс, который происходит до этого. Это сканирование и индексация.
Google ранжирует веб-страницы в своем индексе. Если ваша веб-страница не проиндексирована или неправильно проиндексирована, это повлияет на ваш рейтинг.
Интернет перешел от простого HTML - как SEO, вы можете принять это. Учитесь у разработчиков JS и делитесь с ними знаниями по SEO. JS не уходит. - Джон Мюллер Старший аналитик веб-мастеров
То, что вам нужно знать, это.
Процесс для веб-сайта JavaScript и веб-сайта, не поддерживающего JavaScript, сильно отличается, и именно поэтому JavaScript влияет на ваш рейтинг, если он не выполняется осторожно.
Google сказал в 2014 году что они пытаются лучше понимать веб-страницы, выполняя JavaScript. Но как они на самом деле это делают? И в какой степени они могут визуализировать JavaScripts?
Давайте подробнее рассмотрим весь процесс сканирования и индексации.
Кто или в этом случае что вовлечено в процесс?
Googlebot
Это гусеничный ход, также называемый пауком. Всякий раз, когда появляется новая веб-страница или какие-либо новые обновления на веб-странице, робот Googlebot будет первой точкой контакта с поисковой системой.
Он сканирует веб-страницы и переходит по всем ссылкам на веб-странице. Таким образом, бот обнаруживает больше новых ссылок и новых веб-страниц для сканирования. Просканированные веб-страницы затем передаются в кофеин для индексации .
Имейте в виду, что Googlebot может быть отказано в доступе с помощью robots.txt . Первое, что нужно иметь в виду, если вы хотите, чтобы ваши веб-страницы на основе JavaScript сканировались и индексировались, это не забудьте разрешить доступ для сканеров. Не забудьте также отправить свои URL-адреса в Google с помощью консоли поиска Google, отправив карту сайта XML.
Кофеин
Это индексатор, который был запущен еще в 2010 году , Все, что сканирует робот Googlebot, будет проиндексировано Caffeine, и этот индекс позволяет Google выбирать веб-страницы для ранжирования.
Помимо индексирования просканированного содержимого, Caffeine также делает одну важную вещь, которая также отображает веб-страницы JavaScript. Это очень важно, так как для JavaScript без рендеринга поисковая система не сможет проиндексировать весь контент веб-страницы .
Ссылки, обнаруженные при рендеринге, также будут отправлены обратно в робот Googlebot в очередь на сканирование, что приведет к повторной индексации. Это очень важный момент, который нужно иметь в виду, потому что одна важная часть SEO - это внутренние ссылки. Взаимосвязь ваших веб-страниц на вашем сайте дает Google сильный сигнал о таких вещах, как рейтинг страницы, авторитет и частота сканирования. Что все, в конце дня влияет на рейтинг страницы.
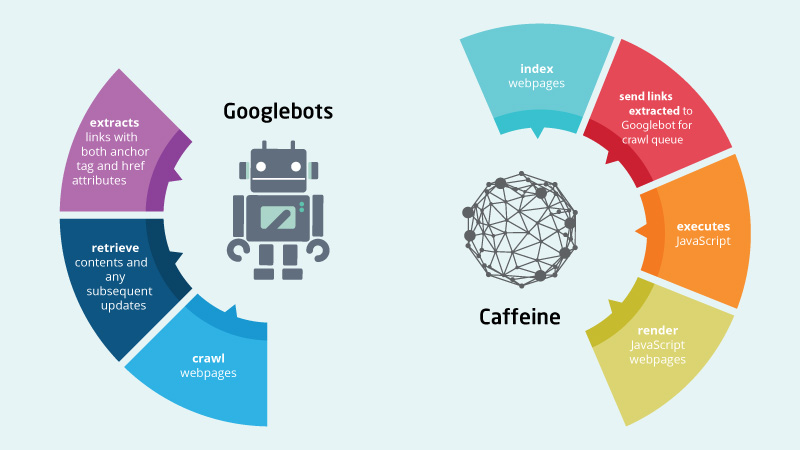
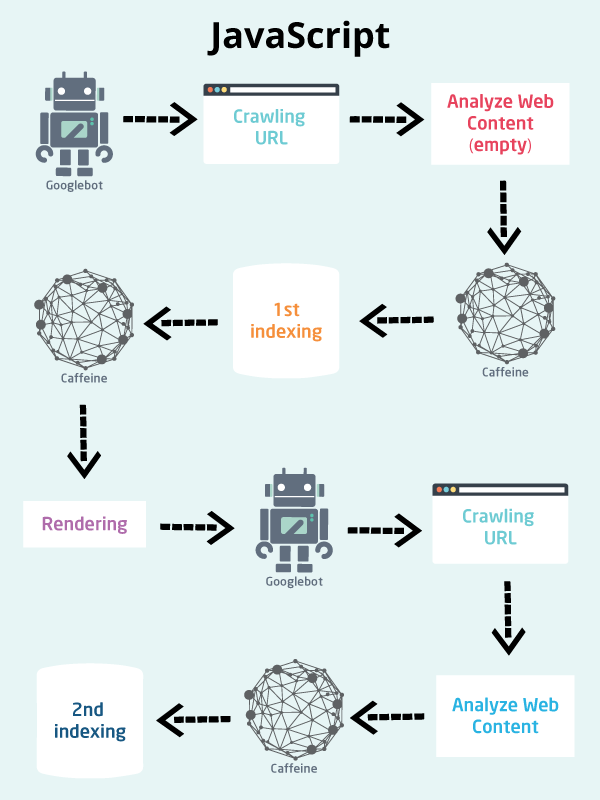
Вот быстрое изображение, которое подводит итог тому, что делают Googlebot и Caffeine.
Процесс сканирования и индексации для веб-страницы на основе JavaScript отличается
Здесь у нас есть простая графика из этого года Google I / O который показывает вам процесс от сканирования до индексации и рендеринга.
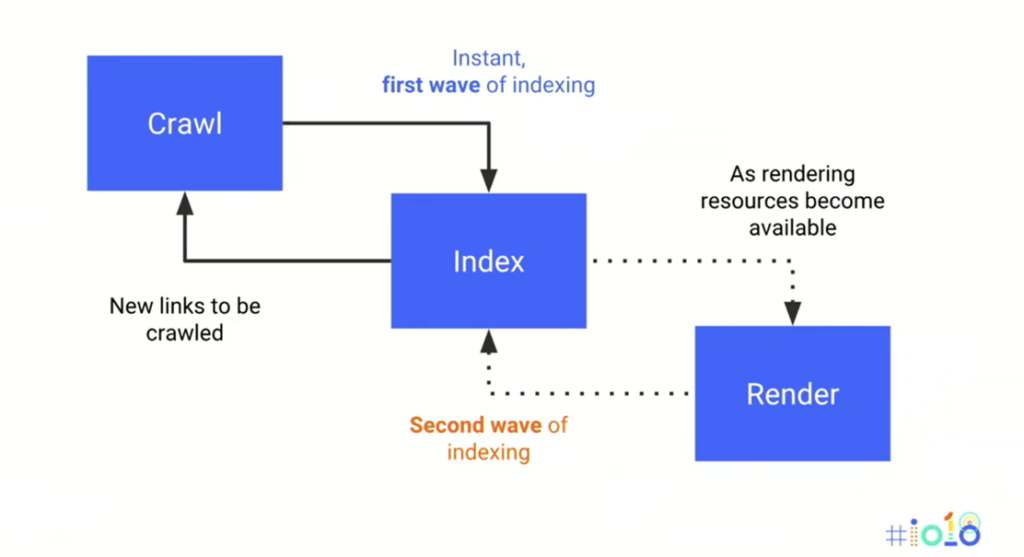
Это хорошо для того, чтобы получить общее представление обо всем процессе, но почему бы нам не приблизиться немного ближе?
Так что же происходит, когда поисковая система достигает ваших обычных страниц, не использующих Java-скрипт, на HTML?
- 1. Googlebot загружает необработанный HTML-файл вашей веб-страницы.
2. Googlebot передает HTML-файл в Caffeine, чтобы извлечь все ссылки и метаданные.
3. Робот Google продолжает сканировать все обнаруженные ссылки.
4. Извлеченный контент индексируется кофеином и используется для ранжирования.
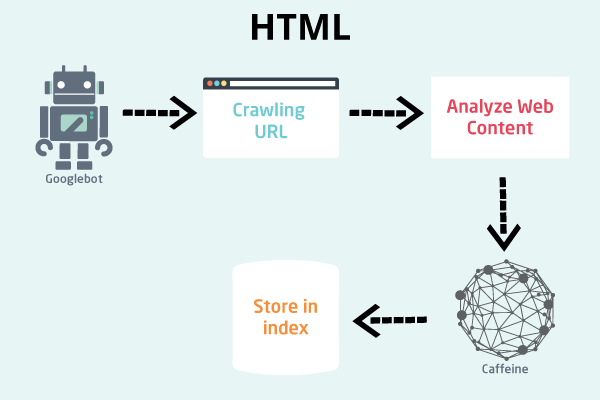
Теперь вот что происходит, когда робот Google достигает вашей веб-страницы JavaScript.
- 1. Googlebot загружает необработанный HTML-файл вашей веб-страницы.
2. Там нет ничего, потому что все скрыто JavaScript.
3. Кофеину нечего индексировать.
4. Ваша веб-страница не имеет рейтинга, потому что там нет контента.
Ну, это был наихудший сценарий и то, что происходит, когда вы не реализуете свой JavaScript способом, который может быть воспроизведен поисковой системой. Так что индексированная версия вашей веб-страницы пуста, насколько беспокоит Google.
Теперь пустые веб-страницы не будут иметь хорошего рейтинга . Вот почему вы должны понимать, как реализовать свой JavaScript таким образом, чтобы он был полностью проиндексирован или как можно ближе к тому, как он выглядит для пользователя, использующего современный браузер.
К счастью, теперь у Caffeine есть возможность отображать ваши файлы JavaScript, как это делает браузер. Google подарил всем SEO и веб-разработчикам большой сюрприз, когда обнаружил, что WRS (служба веб-рендеринга) поисковой системы на самом деле основана на Chrome 41 . С Chrome 69 Появившись в сентябре, поисковая система сильно не в состоянии представить современный JavaScript. Но это лучше, чем ничего, верно?
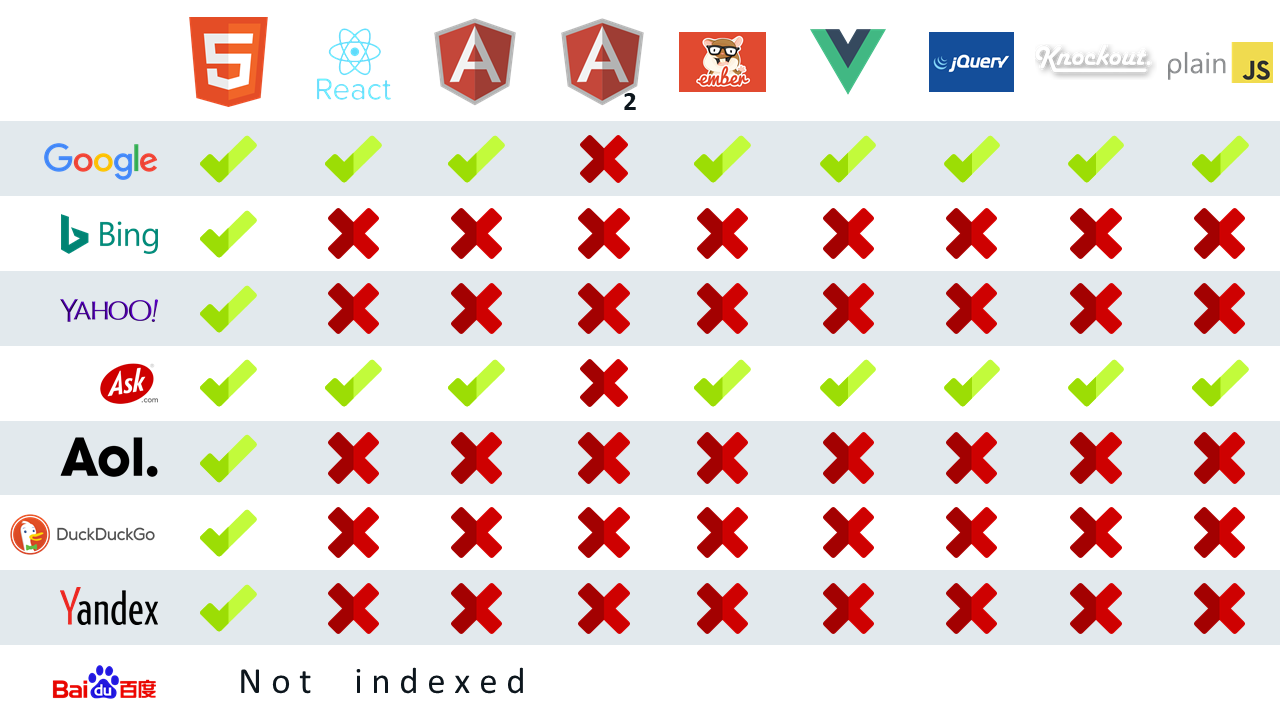
В настоящее время Google возглавляет гонку, поисковая система которой может лучше индексировать ваши веб-страницы JavaScript. (ps: ask.com получает часть своей индексации от неназванной сторонней поисковой системы, я думаю, мы все знаем, кто это…)
Что происходит, когда Google с возможностями рендеринга достигает ваших веб-страниц на основе JavaScript.
- 1. Googlebot загружает HTML-файл вашей веб-страницы.
2. Первая индексация происходит мгновенно без отображаемого содержимого, в то время как Caffeine работает над отображением JavaScript.
3. Любые извлеченные ссылки, метаданные, контент и т. Д. Передаются обратно роботу Google для последующего сканирования.
4. Извлеченный контент индексируется во время второй индексации и используется для ранжирования.
Значит ли это, что Google может без проблем сканировать и индексировать ваши веб-страницы на основе JavaScript? Ну, короткий ответ - нет. Я имею в виду, посмотри на Hulu ,
Google может сканировать JavaScript, но не весь JavaScript. Вот почему так важно реализовать постепенную деградацию ваших веб-страниц. Таким образом, даже если поисковая система не сможет правильно отобразить ваши веб-страницы, по крайней мере, это не будет катастрофическим (подумайте Хулу).
Для Google с поиском JavaScript важно то, что он тяжелый и дорогой . Первая индексация может происходить так же быстро, как они могут индексировать сторону HTML, но важная часть, вторая публикация индексации, будет помещена в очередь, пока у них не появятся свободные ресурсы для этого .
Что означает, представьте себе, вы подали Google еду, но, поскольку у них нет столовых приборов, чтобы съесть ее, они могут только судить, насколько она хороша, по внешнему виду, и сервер не вернется со столовыми приборами, пока они не " Принимая заказы еще от 3 других таблиц, Google опубликовал обзор на Yelp, в котором говорится, что ваша еда - дерьмо.
Звучит ли это справедливо и выгодно? Конечно нет.
Как и скорость сканирования, скорость и частота повторной индексации зависят от нескольких факторов: рейтинг страницы , обратные ссылки, частота обновления, объем посетителей и даже скорость вашего сайта ,
Так как же убедиться, что Google может правильно сканировать, отображать и индексировать ваш сайт JavaScript? Заметьте, не быстро, потому что это совсем другой вопрос.
Два важных инструмента, которые вы можете использовать, чтобы оценить, насколько хорошо Google может сканировать и индексировать ваш сайт JavaScript, используя инструмент извлечения и рендеринга из консоли поиска Google и браузера Chrome 41 (вы можете загрузить браузер здесь Кричи Слону и их офигенному посту Chrome 41 и рендеринг )
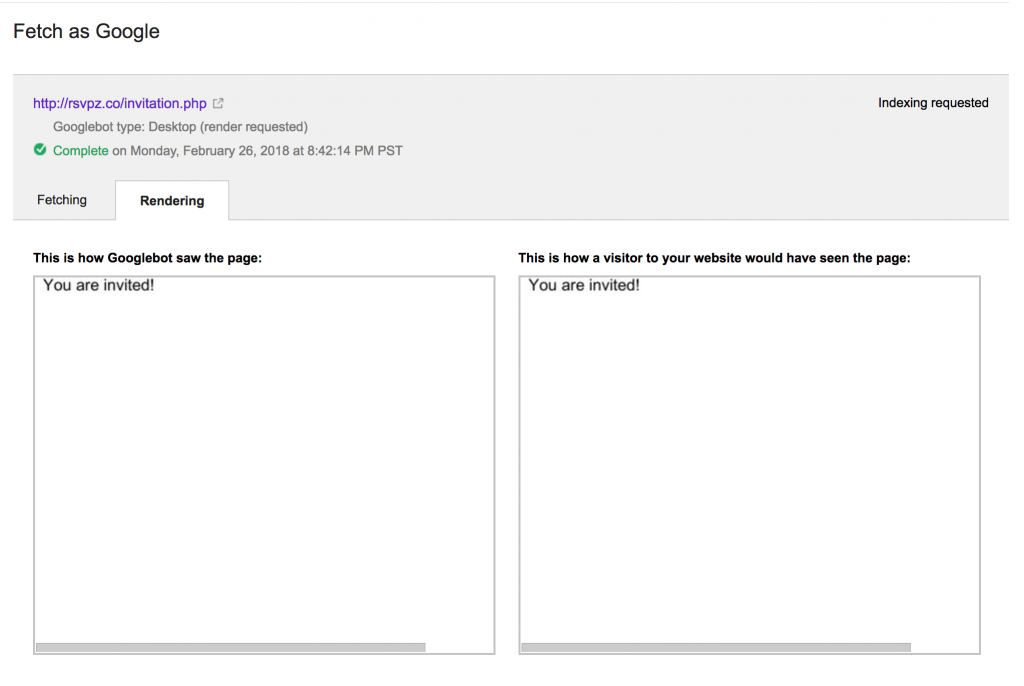
Используйте функцию извлечения как функцию Google, чтобы проверить, может ли поисковая система правильно отображать вашу веб-страницу или нет. (источник)
Вы также можете перейти к Могу ли я использовать чтобы проверить, что поддерживается и не поддерживается в Chrome 41.
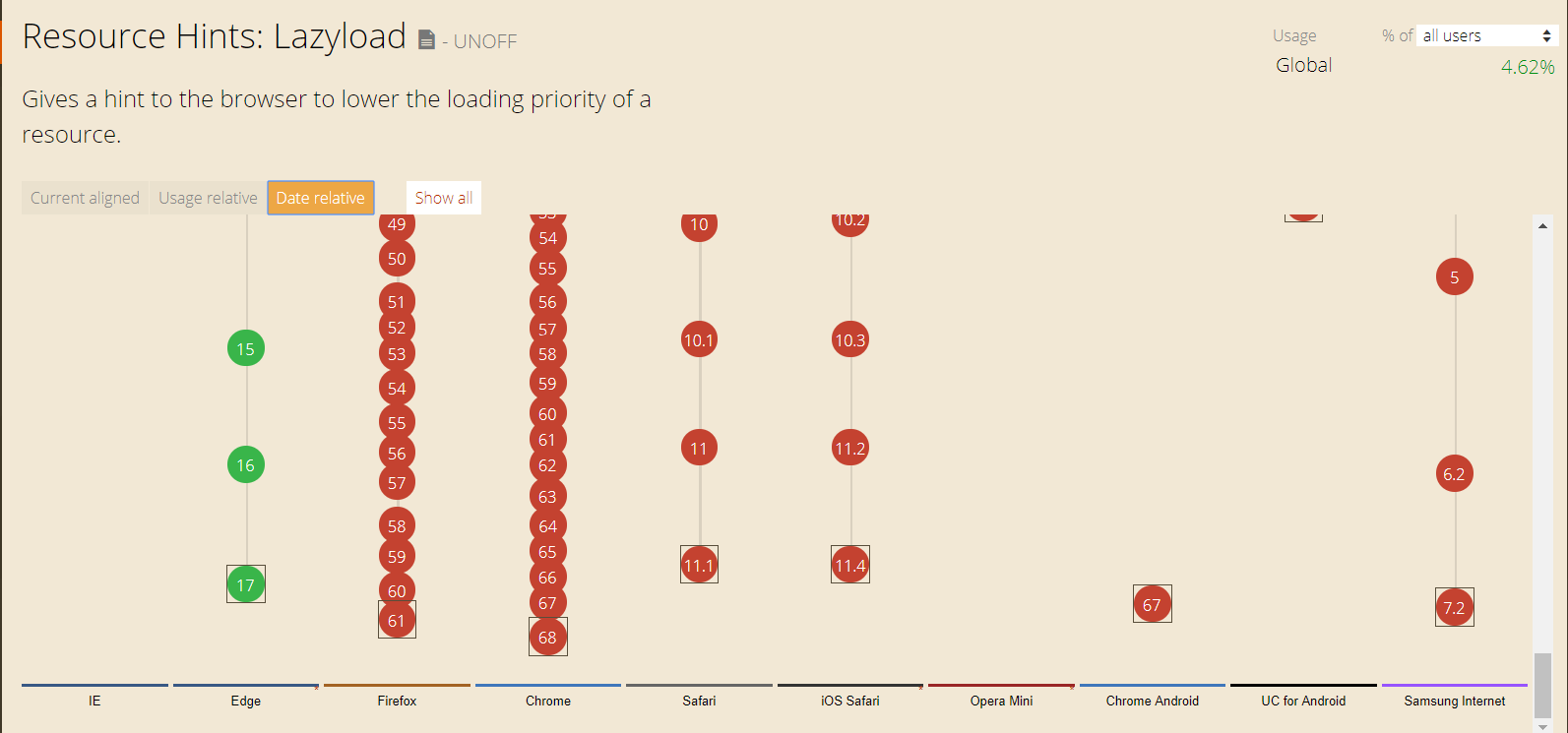
Веб-сайт дает вам четкое представление о том, что поддерживается и не поддерживается всеми версиями браузера. Используйте это, чтобы дважды проверить, может ли ваш сценарий быть выполнен Chrome 41, таким образом, предоставленный Caffeine.
Все это важные инструменты, которые помогут вам понять весь процесс сканирования, рендеринга и индексации. С этим у вас будет лучшее представление о том, где и что пошло не так.
Подвести итоги…
1. Googlebot сканирует, индекс кофеина и рендер.
2. Для веб-страниц HTML робот Google запрашивает страницу и загружает HTML, содержимое которого затем индексируется Caffeine.
3. Для веб-страниц JavaScript, робот Google запрашивает страницу, загружает HTML, сначала выполняется индексация. Затем кофеин рендерит страницу, отправляет обработанные ссылки и данные обратно в робот Googlebot для очереди сканирования, а после повторного сканирования выполняет вторичную индексацию.
4. Рендеринг требует значительных ресурсов, и вторая индексация будет помещена в очередь, что делает его менее эффективным.
5. Используйте инструмент извлечения и визуализации в Google Search Console и Chrome 41, чтобы оценить, насколько хорошо Google может проиндексировать вашу страницу JavaScript.
Вот еще один пост на JavaScript SEO, который может вас заинтересовать: SEO для сайтов на базе JavaScript (резюме Google IO 18)
Полиглот упал в глубокий синий мир SEO и въездного маркетинга, вооруженный пылкой страстью к письмам и увлечением тем, как все крутится во всемирной паутине.
Похожие
SEO поисковая системаВаш веб-сайт вступает "в глаза", когда посещают ваши потенциальные клиенты (люди), но процесс перемещения и индексации его сильно отличается, что делает их "ботами" поисковых систем и каталогов (таких как Google, Yahoo !, Bing). и т. д.). Для того, чтобы этот процесс выполнялся должным образом, необходимо соблюдать основные правила SEO. Для того, чтобы ваш сайт был правильно проиндексирован, а его содержимое наилучшим образом связано с поисковыми системами, поиски пользователей, когда WordPress SEO (поисковая оптимизация)
SEO ( поисковая оптимизация ), также называемая поисковой оптимизацией , оптимизирует веб-сайт для поисковых систем. Если у вас есть сайт о собаках, и вы сделали все возможное, вы, естественно, хотите, чтобы ваш сайт принимал посетителей. Оптимизируя ваш сайт для поисковых систем, таких как Google и Bing, есть вероятность, что вы действительно получите посетителей. Отказ от ответственности: Партнерские ссылки можно найти в Поисковая оптимизация (SEO)
Чтобы сайт был виден в поисковых системах, страницы должны быть хорошо оптимизированы. Чтобы добиться хороших результатов, как техническое качество, так и содержание были разработаны должным образом. SEO - поисковая оптимизация - это работа, которую вы выполняете, чтобы получить наибольшую заметность в поисковых системах в обычном поиске, то есть хиты, которые не являются рекламой. SEM - поисковый маркетинг оплачивается видимость в виде Yoast SEO плагин для WordPress
... Google, когда люди ищут определенные слова или фразы, относящиеся к вашей отрасли, вашим продуктам или вашим услугам. Мы называем эти слова «ключевые слова», и, используя их в стратегических местах на вашем сайте, вы можете увеличить шансы на то, что ваш сайт окажется в поиске по этим терминам. Сейчас существует много, много возможных решений для веб-сайтов для владельцев малого бизнеса, но одна из самых популярных платформ, и, на мой взгляд, одна из лучших, это система управления контентом Seo Race
... чтобы каждый мотивированный человек со схожими интересами мог проверить свои знания и узнать что-то новое. Фраза, которую вы должны быть первой на Google.com при поиске, которая должна быть обязательной в кавычках " seosastezanie SEO Сервис
Важно знать, как SEO улучшает ваш сайт. Как ваши сайты индексируются в верхней части результатов поисковых систем. Мы предоставляем услуги SEO по всему миру. Мы предлагаем услуги SEO по доступным ценам. Если вы действительно хотите получить высокие рейтинги на страницах результатов поисковой системы, то мы можем вам помочь. SEO поможет вам повысить авторитет домена, больше сайтов DA, SEO Сьерра-де-Гуадаррама |
Сьерра-де-Гуадаррама Орнитологический марафон В этом SEO позиционирование
Важность наличия хорошей позиции в поисковых системах Интернета жизненно важна для вашей компании, поэтому мы предлагаем естественное позиционирование во всех наших веб-страницах или магазинах электронной коммерции. Мы применяем методы SEO-позиционирования и на существующих веб-сайтах, где необходимо улучшить их позиционирование в сети. Для этого мы анализируем веб-сайт, изучаем ваш веб-сайт и предлагаем или осуществляем реальные действия по улучшению. Мы Настройки SEO сайта WordPress
... Google XML Sitemap это будет отличная система для создания внешней и динамической карты сайта. Плагины Rich Snippets, поисковые системы, звезды, имена авторов и значки видео для удаления плагина, который вы можете использовать. С помощью плагина Simple Tags вы также можете автоматически устанавливать настройки ссылок на сайте. Наша предыдущая статья Настройки постоянного подключения WordPress Поисковая оптимизация SEO Mississauga
... чтобы ваш целевой рынок находил ваши продукты и услуги в Интернете, Organic SEO - единственный наиболее эффективный способ. Wisevu разработал проверенные временем методы и тактики для ранжирования веб-сайтов по релевантным ключевым словам в основных поисковых системах, включая Google, Bing и Yahoo. Когда дело доходит до рекламы в поисковых системах, таких как Google, Bing и Yahoo, есть только два варианта: органическое SEO и Как выбрать SEO агентство
Прежде всего цена. Вероятно, нет однозначного ответа на это. Но он такой же, как и в любой другой сфере человеческой деятельности. У нас есть два ребра, один супер-дешевый парень по соседству с тем, что он делает на компьютере, и предлагает позаботиться о SEO. Если у вас есть небольшой сайт, где я не знаю, например, вы пишете о природе и хотите, чтобы ваш сайт время от времени находился, у вас
Комментарии
Так что, если Google не считает слова в статье и использует это как фактор ранжирования, почему исследования предполагают, что более длинные статьи будут иметь более высокий рейтинг?Так что, если Google не считает слова в статье и использует это как фактор ранжирования, почему исследования предполагают, что более длинные статьи будут иметь более высокий рейтинг? Это из-за других факторов, связанных с более длинными статьями. Более длинные статьи, как правило, содержат более ценную информацию, что делает их более полезными для читателя. И что Google хочет получить наивысший рейтинг на странице? Удобный, популярный контент. Дело не в количестве слов; это то, Прогнозирование результатов SEO может быть сложной задачей как для маркетологов, так и для агентств, так как же нам правильно понять выгоды от внедрения плана поисковой оптимизации?
Прогнозирование результатов SEO может быть сложной задачей как для маркетологов, так и для агентств, так как же нам правильно понять выгоды от внедрения плана поисковой оптимизации? Хорошо, чтобы начать, как и любой другой маркетинговый проект, вам нужно знать, где вы были, чтобы знать, куда вы идете. Забавно, что маркетологи, знакомые с традиционными СМИ, могут легко оценить производительность, но когда Поисковая «Потому что, если бы мы даже не могли представить, что существует такой грозный осьминог, как этот, то что еще мы даже не рассматривали?
«Потому что, если бы мы даже не могли представить, что существует такой грозный осьминог, как этот, то что еще мы даже не рассматривали?» Вы можете добавить проверочный код как во время установки BAVOKO SEO Tools, так и позже в «Настройки» → «Настройки API», нажав кнопку «Еще не подключен к консоли поиска Google?
Вы можете добавить проверочный код как во время установки BAVOKO SEO Tools, так и позже в «Настройки» → «Настройки API», нажав кнопку «Еще не подключен к консоли поиска Google?» И вставив код из тега HTML. там в строке «Проверка сайта тег HMTL». BAVOKO SEO Tools автоматически сохранит код и сгенерирует метатег на ваших страницах. Вернитесь на страницу GSC и завершите настройку, нажав «Подтвердить». 1. Ранжирование анализов с данными из консоли поиска Google в вашем бэкэнде Не каждый вводит те же термины поиска, что и ключевое слово фокуса, так почему бы вам не использовать синонимы?
Не каждый вводит те же термины поиска, что и ключевое слово фокуса, так почему бы вам не использовать синонимы? Латентная семантическая индексация (LSI) - это математический метод, который связывает поисковые термины и значения. Поскольку существует множество способов поиска одной вещи, сделайте свой контент более естественным и менее повторяющимся, используя связанные ключевые слова поиска. Совет: обязательно включите ключевое слово focus в первый абзац вашего текста. Что такое местный SEO и в чем разница между местным SEO и традиционным SEO?
Что такое местный SEO и в чем разница между местным SEO и традиционным SEO? Возможно, вы даже не знаете, как это работает, но вы уже знакомы с концепцией SEO (поисковой оптимизации), если у вас нет статьи на тему " Что такое SEO? ». Но в двух словах: это процесс получения максимально возможного рейтинга страницы на вашем сайте Google для поиска терминов, имеющих отношение к бизнесу. Но у местного Тем не менее, остается вопрос: если вы можете намеренно заработать себе штраф вручную, почему вы не можете повторить тот же процесс для веб-сайта, который вам не принадлежит?
Тем не менее, остается вопрос: если вы можете намеренно заработать себе штраф вручную, почему вы не можете повторить тот же процесс для веб-сайта, который вам не принадлежит? Возможно, ваше тестирование даст нам некоторое понимание. Дополнительные идеи ручного тестирования штрафов Какая тактика сама по себе, скорее всего, будет замечена и приведет к ручному штрафу? Хорошо известные сети ссылок, скрытый текст, ссылки с оштрафованных сайтов или спам Так что же такое функция Google Maps и как вы получаете от нее клиентов?
Так что же такое функция Google Maps и как вы получаете от нее клиентов? Карты Google - это не только интерактивная карта, но и верхняя часть всех результатов поиска Google. Когда потенциальные клиенты ищут новую компанию или услугу, обычно появляется окно со списком Карт Google. В качестве примера - давайте посмотрим, что происходит, когда вы Google "электрик Норвуд" Что происходит, когда вас кто-то находит, а Google сообщает, что вы закрыты, несмотря на поздний вечер?
Что происходит, когда вас кто-то находит, а Google сообщает, что вы закрыты, несмотря на поздний вечер? Вы только что потеряли продажу. И это только вершина рождественского айсберга. В этой статье рассматриваются 12 простых, действенных улучшений, которые вы можете сделать, чтобы ваш магазин, ресторан или бар включили свой цифровой тракторный луч, и привлекли реальных покупателей из кладовых в этот праздничный сезон. 1. Мобильный сайт Шутки в сторону. мобильный произошел. Так что не так с SEO?
Так что не так с SEO? Сложный спам на SEO Владельцы сайтов часто получают утомительный спам от псевдо-экспертов по SEO с текстом типа « Здравствуйте. Я - специалист по SEO из компании ...... и согласно нашему анализу, по какой-то причине ваш сайт имеет низкую производительность в обычном поиске и трафике. Мы можем помочь вам решить эту проблему и т . Д. ». Часто эти недобросовестные Вы действительно чувствуете, что если SEO не постоят за себя, это может быть конец SEO, как мы его знаем?
Вы действительно чувствуете, что если SEO не постоят за себя, это может быть конец SEO, как мы его знаем? Аарон Уолл: «Я не думаю, что индустрия выросла внезапно, и действительно были статьи о ее неизбежной смерти за годы до того, как я даже вошел в индустрию, поэтому я не думаю, что индустрия умрет быстрой смертью или умрет одновременно. Более вероятно, что люди постепенно маргинализируются, в то время как их прибыль уменьшается, и они теряют личные свободы.
Но как они на самом деле это делают?
Кто или в этом случае что вовлечено в процесс?
Так что же происходит, когда поисковая система достигает ваших обычных страниц, не использующих Java-скрипт, на HTML?
Но это лучше, чем ничего, верно?
Значит ли это, что Google может без проблем сканировать и индексировать ваши веб-страницы на основе JavaScript?
Звучит ли это справедливо и выгодно?
Так что, если Google не считает слова в статье и использует это как фактор ранжирования, почему исследования предполагают, что более длинные статьи будут иметь более высокий рейтинг?
И что Google хочет получить наивысший рейтинг на странице?
Прогнозирование результатов SEO может быть сложной задачей как для маркетологов, так и для агентств, так как же нам правильно понять выгоды от внедрения плана поисковой оптимизации?
«Потому что, если бы мы даже не могли представить, что существует такой грозный осьминог, как этот, то что еще мы даже не рассматривали?